Scaling AI Inferencing on Google Cloud: Why vLLM and GKE Are Setting the New Standard
Smarter, faster AI at enterprise scale

Introduction: From Building AI to Running It Efficiently
For years, the hardest part of AI was training large models. That’s changed. Today, the real challenge isn’t building them - it’s serving them efficiently at scale.
When an enterprise model goes live, every query—every customer chat, inspection alert, or recommendation - becomes a compute event. Each one must be fast, accurate, and cost-efficient.
This is where Google Cloud has quietly taken the lead. By combining A4 VMs powered by NVIDIA B200 GPUs, Virtual Large Language Model (vLLM), and Google Kubernetes Engine (GKE) Autopilot, it’s made large-scale AI inference both accessible and economical.
Recent deployments like DeepSeek v3.1, run on this exact stack, have shown just how far inference performance can go when orchestration and hardware are built to work together.
Why Inference Now Dominates Enterprise AI Economics
Training may be a one-time investment, but inference is forever. Every deployed AI product-from factory sensors to enterprise copilots—depends on fast, reliable inference. And the costs scale linearly with user traffic.
Executives today care less about how many parameters a model has and more about:
- Latency: How quickly can it respond to a customer?
- Scalability: Can it handle a million queries on Monday and ten million on Friday?
- Cost: Are GPUs being used efficiently, or are they sitting idle?
- Reliability: Can the system self-heal and scale without manual tuning?
Google Cloud’s modern inference stack was designed around those exact outcomes.
Where Traditional Inference Architectures Fall Short
Legacy on-prem clusters and even some cloud setups weren’t built for the real-time, bursty workloads that LLMs generate. The result:
- Idle GPUs during off-peak hours, wasting compute dollars
- Manual scaling scripts to meet unpredictable traffic spikes
- Complex network setups that slow data transfer between storage, models, and APIs
- Opaque cost control, where optimization means guesswork
GCP fixes this with a fully managed, auto-scaling inference environment, where GPUs, containers, and model serving software scale together—without infrastructure code.
Inside Google Cloud’s Next-Gen Inference Stack
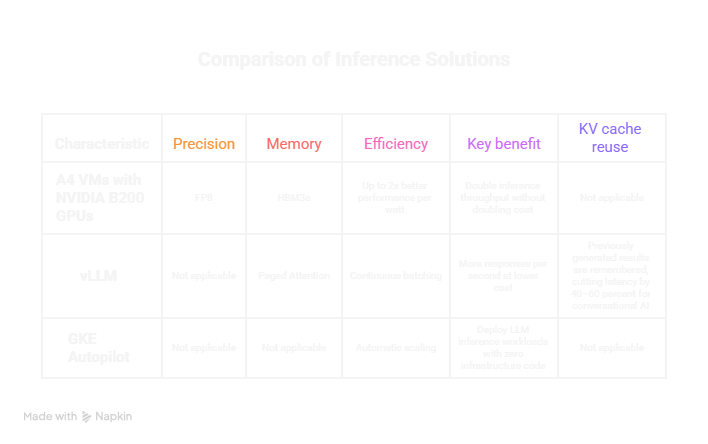
1. A4 VMs with NVIDIA B200 GPUs - Performance and Efficiency in Balance
The A4 VM family introduces NVIDIA’s new Blackwell B200 GPUs, purpose-built for inference.
- FP8 precision: Models run faster by using fewer bits per calculation—8 bits instead of 16-with almost no loss in accuracy.
- HBM3e memory: A next-generation high-bandwidth memory that moves data quickly between GPU cores, reducing bottlenecks when serving large models.
- Energy efficiency: Up to 2× better performance per watt than previous A3 (H100) GPUs, meaning more output for every dollar spent on power.
For enterprises, this means you can double inference throughput without doubling cost.
2. vLLM -The Smart Engine for Large-Scale Model Serving
vLLM has become the open-source gold standard for deploying large language models efficiently.
Its secret sauce:
- Paged Attention: Think of it like a filing system for a model’s memory—it only pulls the pages it needs, saving GPU memory and time.
- Continuous batching: Incoming queries are dynamically grouped, ensuring maximum GPU utilization with minimal wait time.
- KV cache reuse: Previously generated results are remembered, cutting latency by 40–60 percent for conversational AI.
In short, vLLM keeps the hardware busy doing useful work—more responses per second at lower cost.
3. GKE Autopilot -Orchestration Without the Headaches
Running inference isn’t just about GPUs; it’s about orchestrating hundreds of containers and scaling them on demand. That’s where Google Kubernetes Engine (GKE) Autopilot changes the game.
Unlike AWS, where scaling across Inferentia or GPU instances often requires custom setup and manual provisioning, GKE Autopilot integrates GPU scaling natively. Teams can deploy LLM inference workloads with zero infrastructure code—no YAML wrangling, no node tuning.
When traffic spikes, GKE Autopilot automatically:
- Spins up GPU-enabled pods
- Allocates compute resources
- Balances loads across clusters
- Shuts down idle capacity when demand drops
This “hands-off” orchestration is the core differentiator: it turns AI serving into a predictable, managed service rather than an infrastructure project.
Real-World Example: DeepSeek v3.1 on GCP
When DeepSeek released its v3.1 Base model in August 2025, Google Cloud engineers used it to benchmark inference on the new A4 GPUs.
The setup: vLLM running on GKE Autopilot clusters with eight B200 GPUs per node. The results:
- Latency: ~50 ms for short prompts
- Throughput: 2× improvement versus A3 (H100) deployments
- Scalability: Automatic horizontal scaling with no downtime
For enterprises, it validated a key point: open models can perform at enterprise scale when deployed on Google’s native AI infrastructure.
Optimizing for Cost and Speed
Enterprises care about ROI. Here’s how GCP’s inference stack drives it:
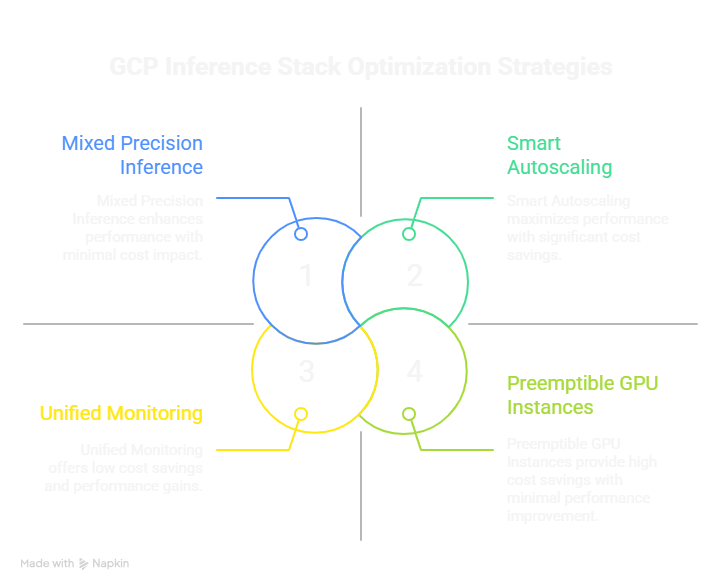
Smart Autoscaling
vLLM’s batching and GKE’s autoscaler expand or shrink capacity in real time. You pay only for the GPUs actually processing requests.
Mixed Precision Inference
FP8 and BF16 precision let models run faster with minimal accuracy loss—20–30 percent faster without retraining.
Preemptible GPU Instances
For batch or non-critical inference, preemptible A4 VMs can cut compute costs by up to 70 percent.
Unified Monitoring
Cloud Operations Suite tracks GPU utilization, latency, and cost per token in a single dashboard—turning performance tuning into data-driven optimization.
Security and Compliance at Scale
Inference often touches regulated or proprietary data. Google Cloud secures it by design.
- Confidential GKE Nodes use Intel TDX to encrypt data even while it’s being processed in memory.
- VPC Service Controls create perimeters that prevent accidental data exfiltration.
- Cloud Armor and IAM manage access and protect endpoints from DDoS attacks.
Together, they enable industries like healthcare, finance, and manufacturing to meet HIPAA, SOC 2, and ISO 27001 requirements without sacrificing performance.
Industry Use Cases
Manufacturing – Predictive Maintenance and Visual Inspection
AI models analyze sensor data and imagery to predict failures before they happen. Sub-second inference means machines stay running instead of sitting idle.
Retail & E-Commerce – Personalized Recommendations
Inference pipelines generate product suggestions in real time. GKE Autopilot handles traffic surges automatically during sales events.
Healthcare – Clinical Summarization and Diagnostics
Large models process medical reports securely inside confidential environments, delivering insights faster while maintaining compliance.
Financial Services – Fraud Detection and Risk Analysis
LLMs sift through unstructured transaction data to flag anomalies. With vLLM on GCP, inference costs drop while detection accuracy improves.
Automotive – Connected Vehicle Intelligence
Edge-deployed inference nodes analyze sensor feeds in milliseconds, enabling safer, smarter driver-assist systems.
Clearer Comparison: Why GCP Leads in Orchestration
| Cloud Provider | Inference Stack | GPU/Chip Option | What Makes It Different |
|---|---|---|---|
| Google Cloud Platform | vLLM + GKE Autopilot + Vertex AI | A4 (B200), A3 (H100) | Key Native GPU autoscaling, no infrastructure code, lower latency via FP8 precision |
| AWS | SageMaker + Inferentia/Trn1 | Inferentia 2, Trn1 | Custom scaling scripts required; strong training chips but inference setup is manual and fragmented |
| Azure | Azure AI Studio + AKS | NDv5 (H100) | Mature ecosystem, but limited vLLM integration and higher network egress costs |
| On-Prem | Custom Kubernetes + vLLM | Varied | Full control, high maintenance and energy overhead |
The “so what”: Unlike AWS, where teams must manually wire scaling logic for Inferentia or GPU nodes, GKE Autopilot provisions and scales GPU workloads automatically. That means faster deployment, fewer DevOps hours, and guaranteed utilization efficiency—critical advantages when running expensive LLM inference at scale.
The Future: From Inference to Intelligent Agents
AI workloads are moving toward multi-agent ecosystems, where multiple specialized models communicate and make decisions collaboratively.
Google Cloud is already preparing for this next step with:
- Agent Development Kit (ADK) for orchestrating multi-model workflows
- Agent-to-Agent (A2A) protocols for secure coordination
- Vertex AI Extensions that connect agents to enterprise systems
All these depend on fast, reliable inference. The better your inference stack, the smarter and more autonomous your agents can be.
Conclusion: Making AI Inference a Competitive Advantage
The AI race is no longer about who trains the biggest model—it’s about who serves it best. Google Cloud’s combination of A4 GPUs, vLLM, and GKE Autopilot delivers that advantage: faster responses, lower costs, and hands-free scalability.
For leaders modernizing operations, this architecture means turning compute efficiency into business velocity.
Ready to transform how you run AI? Explore our Google Cloud Services and see how we help enterprises build production-ready AI systems that scale smarter.
