
Automating A2A Workflows with Azure AI Foundry and Copilot
How Enterprises Can Build Intelligent, Scalable Automation Across Business Applications...

1. Introduction Organizations generate vast amounts of unstructured data daily, including emails,...

What if you want to scale up, ensure backup, and tap into...

Designing Intelligent LLM Systems for Real-Time Decision Making As organizations grapple with...

In a world where customer expectations are at an all-time high, businesses...

Generative AI Meets the Metaverse...

Salesforce Experience Cloud is a powerful platform for building robust, scalable, and...

A Deep Dive into Meta Llama 4 on AWS Bedrock: Capabilities &...
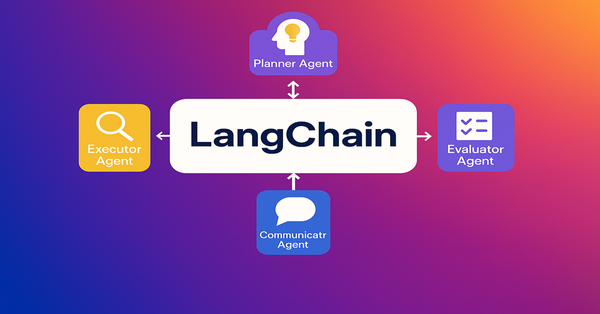
Multi-Agent Orchestration with LangChain...

What's New from Google Cloud Next 2025...