


In this blog post, I’ll explore our strategic evolution in advising a client within the asset condition monitoring sector. Our focus was on transforming complex machine data into intuitive, natural language generated (NLG) reports. This shift aimed to empower asset condition monitoring analysts and field engineers with the ability to effortlessly interpret various metrics presented by the data platform as if they were in plain natural language – English.
Our initial recommendations with NLG 1.0 made sense in early 2022, providing a solid foundation for understanding and communicating asset conditions. The advent of Generative AI & fast adoption of AWS technologies in this space presented us with an opportunity to enhance our recommendation and paved way for NLG 2.0.
Note: This blog post intentionally hides lot of details and altered some information to protect confidentiality
Once Upon a Time – Early 2022
Problem Statement: Asset condition monitoring analysts spend a considerable amount of time drafting lengthy emails or engaging in extended phone calls to convey intricate equipment health information to field engineers. This traditional method of communication not only strains resources but also involves multiple back and forth due to the complexity of the charts and figures involved. There exists a pressing need for a more streamlined, intuitive approach to sharing these insights, ensuring that field engineers receive comprehensive yet accessible reports on potential equipment outages.
High-Level Initial Recommendation – NLG 1.0
The initial recommendation was to combine structured data (measures & dimensions), unstructured data (email and audio transcripts), and past reports to generate intuitive reports that is powered by NLG pipeline and use models such as T5, GPT 1.0, (AL)BERT, and others and refer the asset metadata from the graph system.
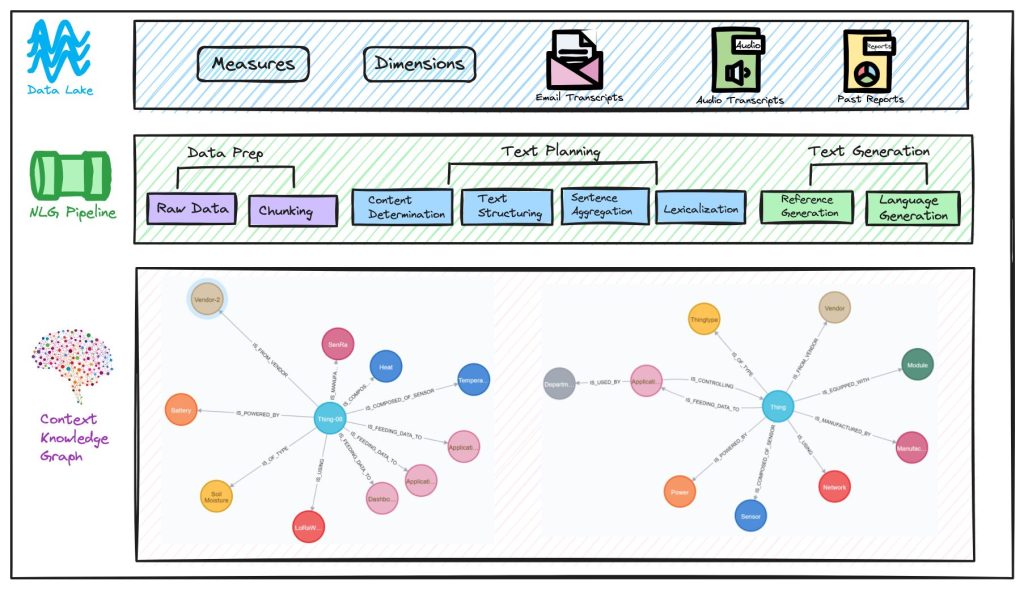
Copyright – Info Services
Heard about Generative AI 🙂
As we were in the midst of developing the necessary data platform and prediction model, the technological landscape underwent significant changes. It’s hard to ignore the transformative wave of Generative AI that swept through the tech world between late 2022 and mid-2023, a phenomenon well-documented across numerous platforms and discussions. This surge in Generative AI innovation prompted us to reassess and adapt our strategy with NLG 1.0, recognizing the need to align our approach with the latest advancements and capabilities offered by this rapidly evolving field.
High-level Revised Recommendation – NLG 2.0
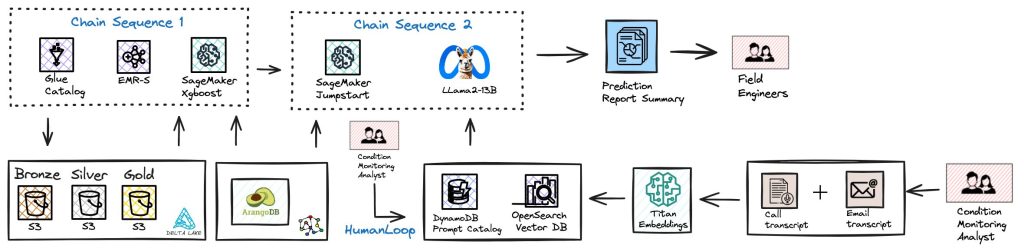
Copyright – Info Services
AWS’s Innovation in Generative AI Offerings
AWS SageMaker Jumpstart
Amazon SageMaker JumpStart serves as a comprehensive platform for enhancing your machine learning (ML) endeavors, streamlining the process of leveraging Foundational Models (FMs) for various tasks. This platform enables swift evaluation, comparison, and selection of FMs, guided by established metrics for quality and ethical considerations, facilitating applications such as summarizing articles and generating images. It offers pretrained models that are adaptable to specific needs and datasets, with straightforward deployment capabilities through its interface or SDK. Moreover, SageMaker JumpStart grants access to ready-made solutions for prevalent challenges and permits the sharing of ML resources, like models and notebooks, to foster rapid development and deployment of ML models across your organization.
Dive into a vast array of both exclusive and openly accessible foundational models suitable for a broad spectrum of activities, including summarizing articles, as well as generating text, images, or videos. These models, being pretrained, can significantly reduce training and infrastructure expenditures while allowing for customization to meet unique requirements.
SageMaker JumpStart boasts an extensive collection of built-in algorithms and pretrained models sourced from renowned model hubs like TensorFlow Hub, PyTorch Hub, Hugging Face, and MxNet GluonCV, accessible through the SageMaker Python SDK. These built-in algorithms span essential ML tasks, including various classifications (image, text, tabular) and sentiment analysis.
Additionally, SageMaker JumpStart offers plug-and-play, comprehensive solutions for numerous standard machine learning scenarios, encompassing demand forecasting, credit risk assessment, fraud detection, and computer vision tasks.
AWS’s Text Embeddings
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
- Optimized for text retrieval and RAG use cases, allowing conversion of text to vectors for precise database searches.
- Serverless model on Amazon Bedrock, accessible via REST API or AWS SDK, requiring text input and modelID.
- Supports up to 8,000 tokens for broad use cases, delivering 1536-dimension vectors for high accuracy and low latency.
- Facilitates multilingual embedding creation and querying in over 25 languages, eliminating the need for separate models per language.
Because Amazon Titan Text Embeddings is a managed model on Amazon Bedrock, it’s offered as an entirely serverless experience. You can use it via either the Amazon Bedrock REST API or the AWS SDK. The required parameters are the text that you would like to generate the embeddings of and the modelID parameter, which represents the name of the Amazon Titan Text Embeddings model. The following code is an example using the AWS SDK for Python (Boto3):
import boto3
import json
# Establish connections with Amazon Bedrock and its runtime service
bedrock_client = boto3.client('bedrock', region_name='us-west-2')
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name='us-west-2')
# Fetch and filter Amazon's foundational models
models_list = bedrock_client.list_foundation_models()
amazon_models = [model for model in models_list['modelSummaries'] if 'amazon' in model['modelId']]
print(amazon_models)
# Setup for model invocation
benefit_request = "Summarize the benefits of AWS Bedrock"
request_body = json.dumps({"inputText": benefit_request})
model_identifier = 'amazon.titan-embed-text-v1'
headers = {'Accept': 'application/json', 'Content-type': 'application/json'}
# Call the model for embeddings
model_response = bedrock_runtime_client.invoke_model(
Body=request_body,
ModelId=model_identifier,
Accept=headers['Accept'],
ContentType=headers['Content-type']
)
# Extract and display the embedding from the response
response_content = json.loads(model_response['Body'].read())
print(response_content.get('embedding'))
AWS’s Vector Databases
Vector databases encode various types of data into vectors using embedding models, capturing the essence and context of the data. This encoding allows for the discovery of similar assets by searching for neighboring data points, enabling unique experiences like searching for images similar to a photograph taken on a smartphone.
Vector databases operationalize embedding models, making application development more efficient with features like resource management, security controls, and sophisticated query languages. They empower developers to create unique experiences, such as searching for similar images using a smartphone photograph. Additionally, they can complement generative AI models by providing an external knowledge base, ensuring the delivery of trustworthy information.
Vector databases accelerate AI application development and simplify AI-powered application workloads’ operationalization. They offer an alternative to building on top of bare k-NN indexes, which require extensive expertise. A robust vector database provides foundational features like data management, fault tolerance, and a query engine, simplifying scaling and supporting security requirements.
AWS offers a range of services tailored for vector database needs:
- Amazon OpenSearch Service: Facilitates interactive log analytics, real-time application monitoring, website search, and more. It supports k-Nearest Neighbor (k-NN) search.
- Amazon Aurora PostgreSQL-Compatible Edition & Amazon RDS for PostgreSQL: These support the pgvector extension, allowing you to store embeddings from ML models in your database and perform efficient similarity searches.
- Amazon Neptune ML: A capability of Neptune that uses Graph Neural Networks (GNNs) for making predictions using graph data.
By leveraging AWS’s offerings, developers can harness the power of vector databases efficiently, creating innovative and user-centric applications.
Conclusion
The AWS ecosystem, with its plethora of services such as SageMaker Jumpstart support with many open, closed and hugging face text models, OpenSearch VectorDB, DynamoDB for prompt catalog to enable human feedback loop, and the foundational strength of AWS Bedrock, forms a comprehensive infrastructure that propels the development and deployment of sophisticated AI applications.
References
- https://aws.amazon.com/sagemaker/jumpstart/
- https://aws.amazon.com/bedrock/
- https://blogs.infoservices.com/data-engineering-analytics/predict-industrial-equipment-health-with-aws-sagemaker-algorithms/
- https://blogs.infoservices.com/data-engineering-analytics/a-timely-solution-for-time-series-data-management-and-analysis-with-aws-timestream/
Author: Raghavan Madabusi