Building Smarter: Why LLMs Are the Next Big Thing for Everyone
LLMs at the Core of Smart Innovation

Large Language Models (LLMs) have emerged as the cornerstone of modern AI applications. Their ability to understand, generate, and reason with human language at scale is unlocking new efficiencies, and redefining how organizations engage with data and users alike. Enterprises are increasingly integrating these capabilities with services like AWS to enable smarter, scalable, and cloud-native solutions.
But as their influence grows, so do the questions. How do LLMs function beneath the surface? What differentiates them from traditional NLP models? And what considerations, technical, ethical, and practical, must guide their adoption?
This in-depth guide offers a strategic exploration of LLMs, covering their architecture, use cases, benefits, limitations, and future potential in enterprise and consumer contexts.
What Are Large Language Models?
Large Language Models (LLMs) are AI systems trained on massive datasets to understand and generate human-like text. They’re built on the transformer architecture, enabling them to interpret and generate language with context, nuance, and even emotion.
Unlike traditional NLP systems, which rely heavily on rule-based or statistical methods, LLMs use transformer architecture to handle context, semantics, and syntax with uncanny fluency. Platforms like AWS Bedrock, explored in our post on enhancing generative AI with guardrails, offer an enterprise-ready way to work with these models responsibly
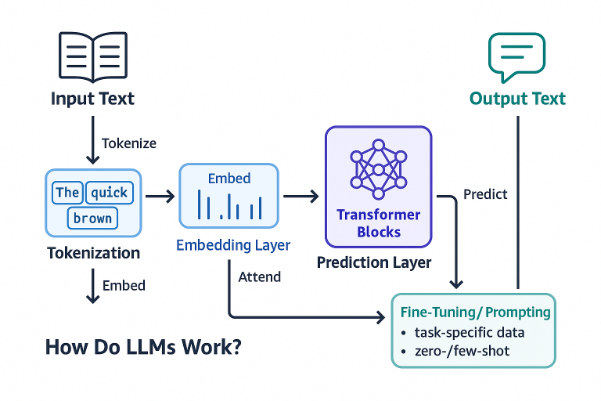
How Do LLMs Work?
At their core, LLMs use deep neural networks called transformers, which excel at handling sequential data like text. These models are trained using self-supervised learning, which means they learn patterns and relationships by predicting masked or next words from context.
1. Training on Massive Data
LLMs are trained on huge corpora of text (books, articles, web content) using self-supervised learning, where the model predicts missing words in sentences.
2. Transformer Architecture
Introduced in the paper Attention Is All You Need, transformers are the backbone of LLMs. They use self-attention mechanisms to weigh the importance of each word in a sentence, helping the model grasp deeper context.
3. Tokenization and Embeddings
Text is broken into "tokens" and converted into vectors that the model can process. This allows the model to recognize patterns and relationships between words—even across long passages.
4. Fine-Tuning and Prompting
After initial training, LLMs are fine-tuned on specific tasks or industries (e.g., legal, healthcare) or prompted through few-shot learning to perform without additional training.
Top Use Cases for LLMs
LLMs are increasingly woven into real-world applications across every industry:
- Customer Support: AI agents resolve up to 80% of Tier 1 support queries, cutting costs and response times.
- Coding Assistance: Tools like GitHub Copilot can auto-complete code and offer suggestions, improving developer productivity by up to 55%.
- Marketing & Content: From blogs and email campaigns to SEO copy, LLMs are automating content at scale.
- Healthcare: Summarizing patient notes, assisting diagnostics, and even translating medical jargon into plain language.
- Legal & Compliance: Reviewing contracts, identifying risks, and summarizing regulations.
- Education: Customizing learning materials, generating quizzes, and tutoring students in real time.
Benefits and Challenges
Benefits:
- Context Awareness: Deep understanding of language, tone, and nuance.
- Versatility: One model, many applications—text generation, summarization, classification.
- Reduced Manual Effort: Automates routine tasks at scale.
- Multilingual Capabilities: Trained on multi-language corpora. as demonstrated in our Natural Language Engine project.
- Open Ecosystem: Access to both proprietary (GPT-4 Turbo, Claude) and open-source LLMs (Mistral, LLaMA 3).
Challenges:
- Hallucinations: LLMs sometimes generate plausible but incorrect information.
- Bias: Inherited from the data they were trained on.
- Environmental Cost: Training LLMs consumes huge amounts of energy.
- Security & Privacy: Risk of data leakage or generating harmful content.
Leading LLM Platforms
Here are some of the most influential LLM platforms available today:
| Platform | Model | Strength |
|---|---|---|
| OpenAI | GPT-4 Turbo | High accuracy, fast inference |
| Meta | LLaMA 3 | Best open source LLM 2025 contender |
| Anthropic | Claude 3 | Safety-focused, long context |
| Mistral | Mistral 7B | Lightweight yet powerful |
| Google DeepMind | Gemini | Multimodal capabilities |
| Hugging Face | Falcon, BLOOM | Community-driven, customizable |
Looking for enterprise-grade options? Explore enterprise LLM solutions from AWS Bedrock, Azure OpenAI, and Google Cloud.
What Are AI Guardrails and Why Do They Matter?
As powerful as LLMs are, they need constraints. AI guardrails are the mechanisms we use to ensure LLMs behave ethically and responsibly:
- Prompt Moderation: Detecting and blocking unsafe or toxic queries.
- Context Filters: Ensuring the model sticks to relevant information.
- RAG (Retrieval-Augmented Generation): Grounding answers in verified data.
- Human Oversight: Integrating review loops and audits.
LLMs vs Traditional NLP Models
Before LLMs, NLP models were trained for specific tasks like sentiment analysis or named entity recognition. They required large labeled datasets and couldn’t generalize well.
LLMs, by contrast, are pre-trained on broad data and then fine-tuned, enabling multi-task performance from a single model.
| Feature | LLMs | Traditional NLP |
|---|---|---|
| Data Input | Entire internet-scale corpora | Smaller, curated datasets |
| Architecture | Transformer-based | RNNs, CNNs, CRFs |
| Performance | State-of-the-art on benchmarks | Task-specific |
| Training Style | Self-supervised, few-shot learning | Supervised, task-specific |
| Adaptability | Highly generalizable across multiple tasks | Requires retraining for each new task |
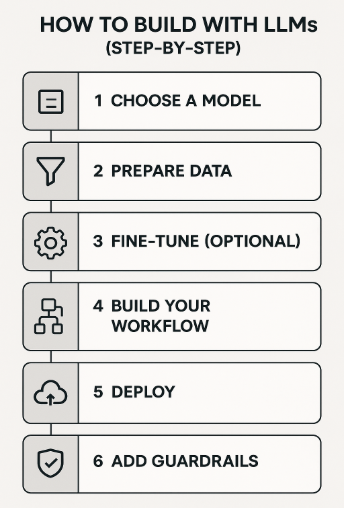
How to Build with LLMs (Step-by-Step)
Here's how to go from idea to implementation:
Step 1: Choose a Model
- Open source vs proprietary LLMs
- Example: Mistral 7B vs Claude (based on use case, budget, and licensing)
Step 2: Prepare Data
- Clean and tokenize your dataset.
- Use Hugging Face datasets or bring your own.
Step 3: Fine-Tune (Optional)
- Fine-tune LLM using Hugging Face tools like Trainer or PEFT.
- Target domain-specific knowledge.
Step 4: Build Your Workflow
- Use LangChain for LLM workflows like chatbots or RAG.
- Integrate with tools like Vector DBs (e.g., FAISS, Pinecone).
Want to know how we built scalable workflows? Check our post on chatbot development with NeMo Guardrails.
Step 5: Deploy
- Deploy LLM on AWS/GCP via Sagemaker, Bedrock, or Vertex AI.
- Monitor, evaluate, and optimize.
Step 6: Add Guardrails
- Use tools like NeMo Guardrails or Amazon Bedrock Guardrails to enforce safety and compliance.
For a hands-on approach to developing a generative AI application, check out our blog on Building an AWSome Generative AI App in Under 50 Hours.
The Future of LLMs
We’re just getting started. LLMs are evolving in exciting ways:
- Multimodal Models: Capable of processing text, image, audio, and video.
- Edge Deployment: Smaller, efficient models for phones and IoT devices.
- Better Transparency: Explainable AI tools to understand model decisions.
- Stronger Governance: Global efforts to set ethical AI frameworks.
Curious about LLaMA 3 release date or GPT-4 Turbo specs? Keep an eye on model cards from Meta and OpenAI.
Final Thoughts
LLMs have redefined what’s possible with AI. Whether you're looking to build a chatbot with LLM, set up a RAG pipeline, or evaluate the best open source LLM 2025, understanding the building blocks—from architecture to governance is key.
As more businesses adopt LLMs, knowing how LLMs are trained, what tools to use, and how to ensure safety and alignment will be non-negotiable. With frameworks like LangChain, platforms like Hugging Face, and cloud providers like AWS and GCP, the toolbox has never been richer, or more powerful. if you're ready to take the next step, explore our LLM and cloud services or connect with us for expert guidance.
FAQ’S
- Can LLMs be tailored to particular industries?
Yes. LLMs can be adapted through domain-specific data to suit industry requirements—such as legal, medical, or financial terminology. This increases relevance, accuracy, and performance and ensures outputs comply with compliance or professional requirements.
2. What is few-shot learning in LLMs?
Few-shot learning enables LLMs to carry out tasks by learning from a limited number of examples within the prompt—without having to retrain the model. This enables faster and more adaptive deployment, particularly in dynamic or low-data environments.
3. Are open-source LLMs safe to use in the enterprise?
Open-source LLMs such as LLaMA 3 or Mistral 7B may be trusted in combination with adequate infrastructure and protection layers. Open-source LLMs are transparent, secure by design, cost-effective, particularly for enterprises with the requirement of customizations or hosting localization.
4. How do I select proprietary and open-source LLMs?
Proprietary LLMs (such as GPT-4 Turbo, Claude 3) provide tuned performance and support, while open-source models allow for flexibility and customization. The decision is based on your budget, compliance requirements, performance requirements, and technical skill levels.
5. What infrastructure is required to deploy LLMs?
LLMs demand high-end compute environments, usually relying on GPUs or TPUs. Cloud platforms such as AWS SageMaker, Google Vertex AI, and Azure ML provide scalable deployment facilities. Vector databases, API gateways, and monitoring tools also have important roles to play in production environments.