Harnessing the Future: Azure AI Foundry Meets LLaMA 4

The generative AI is evolving at breakneck speed and Microsoft’s Azure AI Foundry paired with Meta’s LLaMA 4 represents one of the most compelling partnerships shaping that evolution. Together, they offer a paradigm shift from chasing closed, monolithic AI models to embracing open, adaptable, and scalable AI systems.
The Rise of System-Centric AI
Over the past year, generative AI has moved from novelty to necessity. According to a McKinsey report, nearly 60% of organizations are now piloting or using generative AI in some form. Yet, many struggle with model governance, integration with proprietary data, and balancing performance with compliance.
What is Azure AI Foundry?
Azure AI Foundry is Microsoft’s bold move to simplify the end-to-end journey of building generative AI applications. It's a managed service that combines:
- Curated open models (like LLaMA 4, Mistral, Phi-3)
- Custom model training & fine-tuning workflows
- Integration with enterprise data lakes
- Built-in safeguards, evaluations, and cost monitoring
Why LLaMA 4?
Meta’s LLaMA 4 (Large Language Model Meta AI) is the next-gen evolution of the LLaMA series that is open-weight, research-grade models that continue to punch well above their parameter count. With improved reasoning, multilingual fluency, and instruction-following capabilities, LLaMA 4 positions itself as a competitive alternative to proprietary models like GPT-4 or Claude 3.
What makes LLaMA 4 a game-changer in the enterprise context is its fine-tunability and transparency qualities that Azure AI Foundry is built to amplify.
A Shift from Model-Centric to System-Centric AI
We’re now entering a phase where model access is no longer the differentiator; however, how you integrate and operate AI systems is.
Azure AI Foundry + LLaMA 4 reflects this shift:
- Bring your own data: Easily ground LLaMA 4 on proprietary knowledge through Retrieval-Augmented Generation (RAG).
- Evaluate iteratively: Use Azure’s built-in eval tools to compare outputs across models and prompt variations.
- Customize safely: Guardrails and audit tools keep your custom LLaMA 4 applications aligned with compliance and ethical standards.
- Deploy flexibly: Host the model on Azure endpoints or integrate with Microsoft Copilot stack.
LLaMA 4 in Azure AI
Microsoft and Meta are bringing LLaMA 4's Scout and Maverick variants directly into the Azure AI ecosystem as managed compute offerings, unlocking powerful new capabilities:
Available Models:
- LLaMA-4-Scout-17B-16E
- LLaMA-4-Scout-17B-16E-Instruct
- LLaMA-4-Maverick-17B-128E-Instruct-FP8
These models offer first-class support for multimodal input, processing text, images, and even video frames with a unified model backbone, setting the stage for next-gen applications that require deep reasoning, visual understanding, and contextual awareness.
What’s New in LLaMA 4? Key Architectural Innovations
Meta has reengineered the foundation of its models in LLaMA 4, prioritizing efficiency, scale, and multimodal capabilities.
1. Early-Fusion Multimodal Transformer
Rather than bolting on modality support, LLaMA 4 introduces native early fusion, where all input types (text, images, video frames) are converted into a common token format from the start. This means:
- Richer cross-modal understanding
- Seamless document+image analysis
- Better integrated responses in chat and assistant use cases
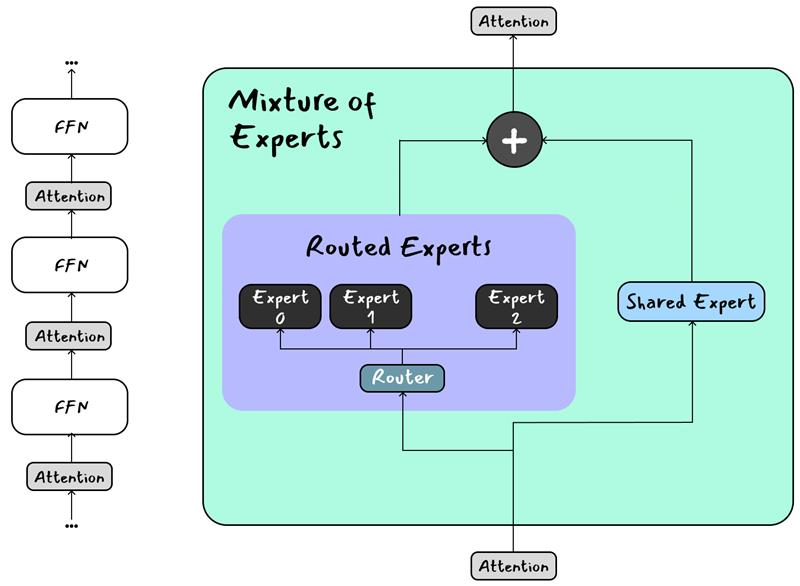
2. Sparse Mixture of Experts (MoE) for Scalable Inference
LLaMA 4 adopts a sparse MoE architecture, using 128 expert models, of which only a few are active per input. This provides:
- 400 billion total parameters
- 17 billion active per query, optimizing compute
- High performance at lower cost
This design allows organizations to deploy sophisticated AI at production scale without massive GPU footprints.
LLaMA 4 Scout Models
The Scout family is engineered for long-context, multimodal understanding. It supports an industry-leading 10 million token context length, which is a massive jump from LLaMA 3's 128K.
Available Models:
- LLaMA-4-Scout-17B-16E
- LLaMA-4-Scout-17B-16E-Instruct
Key Specifications:
- 17 billion active parameters
- 16 experts in Mixture-of-Experts architecture
- Supports up to 10 million tokens of context (a major leap from LLaMA 3’s 128K tokens)
- Optimized for inference on a single H100 GPU
Use Cases:
- Enterprise summarization: Analyze an entire knowledge base, parse multiple legal contracts, or summarize historical case data with full context.
- Software development: Parse and understand large codebases to assist with debugging or documentation.
- Hyper-personalization: Process detailed user activity logs for contextualized recommendations or behavioral insights.
What Makes Scout Special?
It handles long-range dependencies, remembering and relating concepts introduced hundreds of pages earlier. With its small expert set (16E), it balances efficiency with depth, making it suitable for organizations that need deep context but are GPU-cost-sensitive.
LLaMA 4 Maverick Models
Maverick is LLaMA 4's high-end conversational workhorse that is engineered for speed, creativity, and cross-lingual capability in dynamic environments.
Available Models:
- LLaMA-4-Maverick-17B-128E-Instruct-FP8
Key Specifications:
- 17 billion active parameters
- 128 experts in a sparse Mixture-of-Experts configuration
- 400 billion total parameters across experts
- Supports 12 languages natively
- Uses FP8 quantization for reduced memory use and faster inference
Use Cases:
- Conversational agents: Advanced customer support, multilingual chatbots, or AI copilots for business users.
- Multimodal tasks: Visual question answering, creative storytelling with images, or summarizing video transcripts.
- Global business: Build enterprise assistants that serve customers or employees across linguistic and geographic boundaries.
What Makes Maverick Special?
- Large expert pool (128E) that’s results in increased capacity and nuanced responses.
- Multilingual + multimodal enables broader reach for global applications.
- FP8 precision that speeds up inference while preserving output quality.
- Flagship conversational model leads to optimized for tone, relevance, and fluency.
Meta reports that Maverick outperforms LLaMA 3.3 70B in most conversational benchmarks while being more cost-efficient to run.
Both Scout and Maverick are distilled from LLaMA 4 Behemoth which is Meta’s most powerful model yet with 288B active parameters and 16 experts. Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM benchmarks like MATH-500 and GPQA Diamond.
Powered by a mixture-of-experts (MoE) architecture, early fusion multimodality, MetaCLIP-based vision encoders, and FP8 training, these models bring scalable intelligence to text, image, and video inputs. As a result, faster inference, efficient deployment, and robust performance across general-purpose AI workloads is now openly available on llama.com and Hugging Face.
Llama 4 Behemoth is a preview of Meta’s 2T-parameter teacher model, with 288B active parameters across 16 experts. It led the co-distillation of Llama 4 Maverick, enhancing student models via a novel dynamic distillation loss. Behemoth’s training required major RL infrastructure revamps and innovations like mixed-capability batching, hard prompt sampling, and system instruction diversity.
Safety & Governance: Meta have integrated multilayered safeguards, from data filtering to Llama Guard, Prompt Guard, and CyberSecEval, for a secure, customizable developer experience. The GOAT red-teaming framework simulates realistic adversaries, boosting risk coverage and response.
Bias Mitigation: Llama 4 significantly reduces refusal rates and political leaning compared to prior versions, down from 7% to <2% refusals and half the political bias rate of Llama 3.3. Meta continues to prioritize balanced, viewpoint-inclusive responses.
Open Access & Ecosystem: Llama 4 Scout and Maverick are open-sourced via llama.com and Hugging Face, with support for cloud, edge, and integrators to follow. The Llama 4 stack is designed to support human-like interaction, speed, and personalization across the evolving open ecosystem.
Built-In Safety, Tunability, and Trust
Meta and Microsoft both recognize the importance of safe, controllable AI. LLaMA 4 integrates security at every layer:
- Pre-training safety filters
- Post-training alignment tuning
- System-level mitigations to prevent prompt injection and adversarial use
When deployed via Azure AI Foundry, LLaMA 4 gains additional protections:
- Azure Content Safety for toxicity detection
- PromptFlow for controlled prompt engineering
- Azure Monitoring for real-time observability and drift detection
The Power in Open Weights + Closed Infrastructure
It might sound paradoxical, but the real magic lies in combining open-weight models like LLaMA 4 with enterprise-grade infrastructure like Azure. This approach empowers businesses to:
- Avoid vendor lock-in
- Maintain full visibility into model behavior
- Leverage cloud-native orchestration, GPUs, and compliance tooling
One can get the creativity of open-source, with the reliability of an enterprise-ready backbone.
What This Means for Enterprises
For organizations looking to innovate responsibly with generative AI, the Azure AI Foundry + LLaMA 4 combo is a blueprint. From copilots and streamlined workflows to next-gen customer interactions, this partnership empowers you to innovate rapidly that too without sacrificing stability.
- Fine-tunability: Open weights mean enterprises can train the model on proprietary datasets without depending on third-party APIs or data-sharing.
- Transparency: Organizations can inspect, validate, and govern the model internally.
- Performance: Benchmarks suggest LLaMA 4 competes closely with GPT-4 and Claude 3 on reasoning and coding tasks, often with fewer compute resources.
According to Stanford’s HELM evaluation (March 2025), LLaMA 4 ranks in the top 5 across multitask language understanding, few-shot reasoning, and instruction-following fidelity.
LLaMA 4 + Azure AI Foundry: What It Unlocks
Bringing LLaMA 4 into the Foundry ecosystem amplifies its strengths. Here’s what enterprises can now do:
- Ground LLaMA 4 with Internal Knowledge
Using Azure’s Retrieval-Augmented Generation (RAG) capabilities, you can augment LLaMA 4 with domain-specific data from policy documents to product manuals, thereby ensuring responses are accurate, relevant, and context-aware. According to Gartner, Enterprises that use RAG experience a 35-50% increase in response accuracy in customer service and internal search use cases.
- Rapid Evaluation & Comparison
Azure Foundry includes evaluation pipelines that let teams compare LLaMA 4’s outputs against other models (e.g., GPT-4, Claude, or even Phi-3) for specific tasks like summarization, classification, or generation.
- Customization with Control
Fine-tuning LLaMA 4 on-prem or within a private Azure environment. Incorporating human feedback using RLHF or supervised learning techniques, all within Azure’s scalable infrastructure.
- Governance by Design
Tracking data lineage, model decisions, and audit trails. Azure’s Responsible AI dashboard integrates directly into Foundry, helping ensure AI systems align with internal policies and industry regulations (e.g., GDPR, HIPAA).
Stats That Matter
- 74% of enterprise leaders say explainability is a critical barrier to scaling GenAI (Accenture, 2024). Open models like LLaMA 4 reduce this friction.
- 58% of organizations using fine-tuned open models report cost savings of 30–50% compared to proprietary API usage (Forrester, Q1 2025).
- Microsoft Azure now supports over 160,000 custom fine-tunes per month through its AI infrastructure.
Real-World Use Cases
- Legal Document Summarization
A global law firm fine-tunes LLaMA 4 on legal documents, enabling lawyers to generate case summaries 80% faster, while keeping sensitive data on-prem.
- Retail Product Copilots
A fashion e-commerce brand uses LLaMA 4 via Foundry to build a chatbot that understands brand tone, customer history, and catalog nuances, leading to a 20% increase in conversion rates.
- Healthcare Compliance Chatbots
With Azure's built-in evaluation and guardrails, a healthcare provider deploys LLaMA 4-powered assistants that answer patient queries while staying HIPAA-compliant.
The Bottom Line
In 2023, the GenAI race was about who had the biggest model. In 2025 and beyond, it’s about who can use models most responsibly, creatively, and efficiently. With LLaMA 4’s transparency and Azure AI Foundry’s enterprise orchestration, organizations now have a framework to build trustworthy, cost-effective, and domain-specialized AI systems at scale.
If you're navigating the complexities of GenAI adoption and looking for open, modular, and enterprise-ready solutions, LLaMA 4 on Azure AI Foundry is well worth your attention. Connect now to get started!