Amazon Kendra — Machine Reading Comprehension


Amazon Kendra is an easy to use enterprise search service that’s powered by machine learning. Kendra delivers powerful natural language search capabilities to your websites and applications so your end users can more easily find the information they need within the vast amount of content spread across your enterprise. Kendra was announced in Re-invent 2019 and now in GA.
Natural language understanding for multiple domains
Kendra uses deep learning models to understand natural language queries and document content and structures for a wide range of internal use cases like HR, operations, support, and R&D. Kendra is also optimized to understand complex language from domains like IT, financial services, insurance, pharmaceuticals, industrial manufacturing, oil and gas, legal, media and entertainment, travel and hospitality, health, HR, news, telecommunications, mining, food and beverage, and automotive. This means that you can ask a question like “Can I add children as dependents on HMO?” and Kendra will provide answers related to your healthcare options
Kendra PoC
Two PoC’s are performed based on different type of documents and the results were impressive. Both PoC’s are performed on the same Kendra instance and involved the following process:
- Identified two documents: 50 short stories (47 pages) & condensed version of Ramayana (Mythology) with multiple short chapters (~ 200 pages)
- These documents are uploaded to a new S3 bucket
- A Kendra instance was created and placed it in appropriate VPC and subnet
- Created necessary roles so that Kendra can access the KMS service & S3 bucket
- Added S3 bucket as the data source to Kendra instance and initiated the indexing process
- Once the index process is complete, we can go to Kendra search UI and start asking different questions that are both straight forward and reasoning based questions where the answer is split into multiple words across paragraphs.
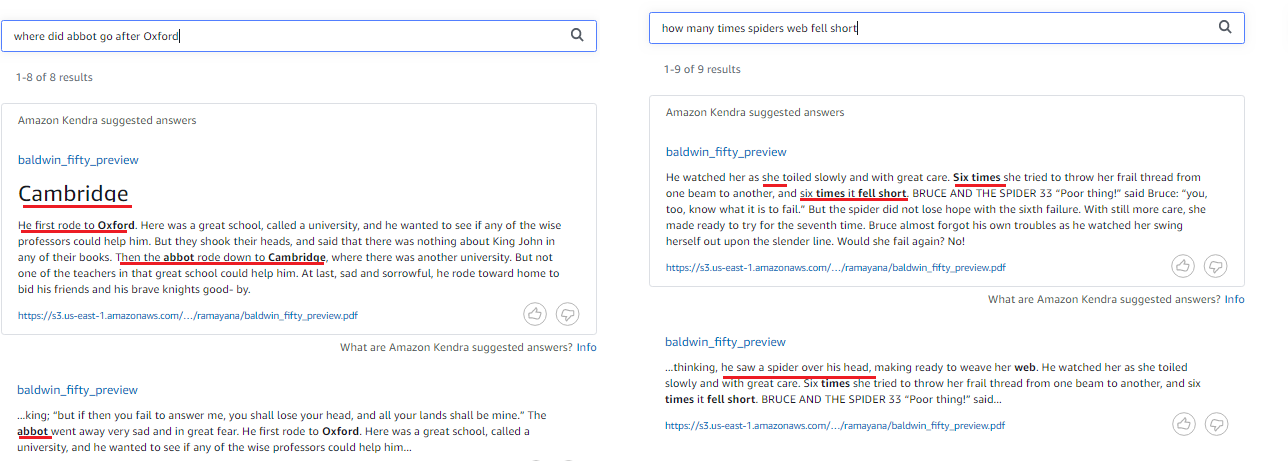
Search 50 Short Stories
50 short stories are independent stories each with 1 to 3 pages long. Each story can have character and context reference from previous paragraph of the same chapter

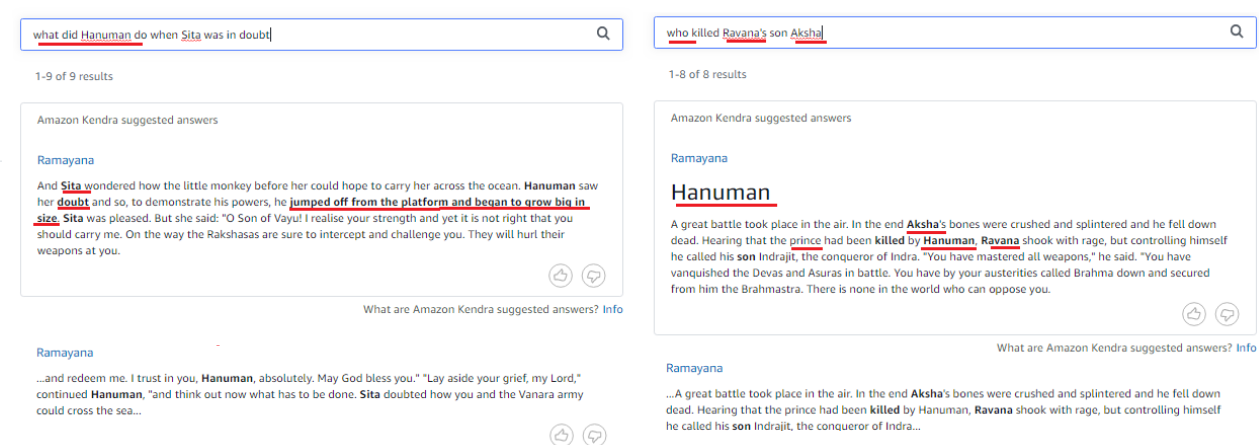
Search Ramayana
Ramayana document has 75 chapters and some chapters refer characters & context from previous chapters



That’s it
Amazon Kendra holds lot of promise in the area of machine reading comprehension and has capabilities to feed in known question and answer set for the model to train on custom documents so that it can provide more meaningful suggestion.It has good features of answering who, what, where, when, etc and also can remember the context in the few paragraphs before.
Take a look at Kendra features: https://aws.amazon.com/kendra/features/
Author: Raghavan Madabusi