Bridging the Gap: GraphQL Schemas for Graph Data Modeling in AWS Neptune

Data modeling for graph databases has traditionally been a challenging task compared to relational databases, where entity-relationship diagrams (ERDs) provide a clear and standardized way to visualize the data model. With graph databases, representing the intricate web of nodes, relationships, and edges can be complex and difficult to communicate effectively. However, the introduction of the Amazon Neptune utility for GraphQL has brought a significant relief to this problem by allowing developers to express their graph data models using the familiar GraphQL schema syntax, enhanced with custom directives.
GraphQL Schemas for Graph Data Modeling
The Amazon Neptune utility for GraphQL provides a concise and intuitive way to define the structure of your data, including the types, fields, and relationships between them. By leveraging this schema-first approach, developers can now easily conceptualize and document their graph data models, making it easier to collaborate and share their designs with others. Moreover, this utility provides a convenient way to create and manage GraphQL APIs backed by a Neptune graph database.
Custom Directives: Bridging the Gap
The true game-changer in this approach is the use of custom directives within the GraphQL schema. These directives act as a bridge between the GraphQL world and the underlying graph database, allowing developers to explicitly map their GraphQL types and fields to the corresponding nodes, edges, and properties in the graph.
A Practical Example: Social Media Data Modeling
To illustrate the power of this approach, let’s consider a social media application where users can create posts, leave comments, like posts, and follow other users. Here’s how the data model could be represented using a GraphQL schema with custom directives. These directives provide a clear and expressive way to model the intricate connections within the graph data structure.
type User @alias(property: "user") {
id: ID! @id
name: String!
email: String!
posts: [Post] @relationship(edgeType: "POSTED", direction: OUT)
comments: [Comment] @relationship(edgeType: "COMMENTED", direction: OUT)
likes: [Like] @relationship(edgeType: "LIKED", direction: OUT)
followers: [User] @relationship(edgeType: "FOLLOWS", direction: IN)
following: [User] @relationship(edgeType: "FOLLOWS", direction: OUT)
}
type Post @alias(property: "post") {
id: ID! @id
content: String!
author: User! @relationship(edgeType: "POSTED", direction: IN)
comments: [Comment] @relationship(edgeType: "COMMENTED_ON", direction: OUT)
likes: [Like] @relationship(edgeType: "LIKED", direction: OUT)
}
type Comment @alias(property: "comment") {
id: ID! @id
content: String!
author: User! @relationship(edgeType: "COMMENTED", direction: IN)
post: Post! @relationship(edgeType: "COMMENTED_ON", direction: IN)
}
type Like @alias(property: "like") {
id: ID! @id
user: User! @relationship(edgeType: "LIKED", direction: IN)
post: Post! @relationship(edgeType: "LIKED", direction: IN)
}
type Query {
getUserByEmail(email: String!): User
@graphQuery(statement: "g.V().has('user', 'email', '$email').fold()")
getPostsByUser(email: String!): [Post]
@graphQuery(statement: "g.V().has('user', 'email', '$email').outE('POSTED').inV().fold()")
getCommentsForPost(postId: ID!): [Comment]
@graphQuery(statement: "g.V().has('post', 'id', '$postId').outE('COMMENTED_ON').inV().fold()")
getLikesForPost(postId: ID!): [Like]
@graphQuery(statement: "g.V().has('post', 'id', '$postId').outE('LIKED').inV().fold()")
getUserFollowers(email: String!): [User]
@graphQuery(statement: "g.V().has('user', 'email', '$email').inE('FOLLOWS').outV().fold()")
getUserFollowing(email: String!): [User]
@graphQuery(statement: "g.V().has('user', 'email', '$email').outE('FOLLOWS').inV().fold()")
}@iddirective identifies the field that represents the unique identifier of a node- @alias directive maps the GraphQL types to their corresponding node labels in the graph database
@relationshipdirective defines the relationships between types, specifying the edge type and direction- @graphQuery or @cypher directives can be specified to the Query or Mutation types.
AWS Neptune GraphQL Resolvers for AppSync
The Amazon Neptune utility for GraphQL provides a convenient way to create and manage GraphQL APIs backed by a Neptune graph database. Here are the details on how to run this utility to create the required resources on AWS AppSync, including the GraphQL endpoint and necessary resolvers:
Starting from a GraphQL Schema
If you already have a GraphQL schema defined, you can use the utility to create the AppSync API and other required resources based on that schema. The schema file should include the GraphQL types, queries, and mutations you want to expose.
neptune-for-graphql \
--input-schema-file your-graphql-schema.graphql \
--create-update-aws-pipeline \
--create-update-aws-pipeline-name your-api-name \
--create-update-aws-pipeline-neptune-endpoint your-neptune-endpoint:port \
--output-resolver-query-https--input-schema-file: Specifies the path to your GraphQL schema file.--create-update-aws-pipeline: Instructs the utility to create or update the AWS resources.--create-update-aws-pipeline-name: Specifies the name for your new GraphQL API.--create-update-aws-pipeline-neptune-endpoint: Provides the endpoint URL and port for your Neptune database.--output-resolver-query-https: Generates the resolver code to handle queries and mutations over HTTPS.
The utility will analyze your schema and create an extended version based on your types. It will add queries and mutations for the nodes stored in the graph database, and if your schema has nested types, it will add relationships between the types stored as edges in the database.
Starting from an Existing Neptune Database
If you already have data in your Neptune database, the utility can scan the database and infer a GraphQL schema based on the existing nodes, edges, and properties.
neptune-for-graphql \
--input-graphdb-schema-neptune-endpoint your-neptune-endpoint:port \
--create-update-aws-pipeline \
--create-update-aws-pipeline-name your-api-name \
--output-resolver-query-https--input-graphdb-schema-neptune-endpoint: Specifies the endpoint URL and port for your Neptune database.--create-update-aws-pipeline: Instructs the utility to create or update the AWS resources.--create-update-aws-pipeline-name: Specifies the name for your new GraphQL API.--output-resolver-query-https: Generates the resolver code to handle queries and mutations over HTTPS.
When you run the utility, it creates the following AWS resources:
- AWS AppSync GraphQL API: The utility creates a new GraphQL API in AWS AppSync based on your schema or the inferred schema from your Neptune database.
- IAM Roles: It creates two IAM roles: one for the AppSync API to invoke the Lambda function, and another for the Lambda function to access the Neptune database.
- AWS Lambda Function: The utility generates a Lambda function that contains the GraphQL resolver code. This function queries the Neptune database based on the incoming GraphQL requests.
- AppSync Data Source: It configures the Lambda function as a data source for the AppSync API.
- AppSync Resolvers: It creates resolvers for the queries and mutations defined in your GraphQL schema, mapping them to the Lambda function data source.
After the utility completes execution, you can find the new GraphQL API in the AWS AppSync console. You can test the API using the “Queries” section in the AppSync console or integrate it with your application.
The utility simplifies the process of creating and managing GraphQL APIs backed by Neptune databases, automating the creation of the required AWS resources and generating the resolver code based on your schema or existing database structure.
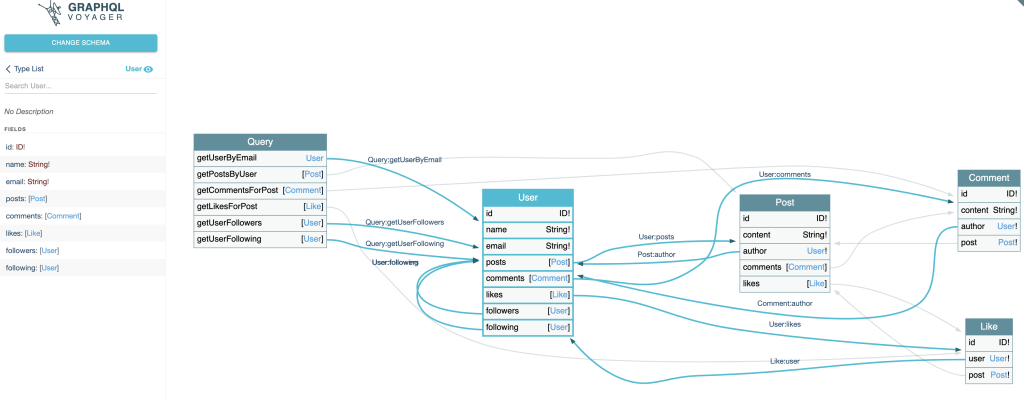
Visualize GraphQL Schema with Voyager
With graphql-voyager, you can visually explore your GraphQL Schema as an interactive graph. This is a great tool when designing or discussing your data model.
Using our Social Media GraphQL schema SDL, it’s easy to import into Voyager and share the schema with other team members for them to easily understand and visualize different nodes, edges, and their relationships.
Conclusion
The ability to effectively model and represent complex, interconnected data structures is crucial in today’s data-driven world. Graph databases, with their inherent capability to handle intricate relationships, have emerged as a powerful solution for applications that require traversing and querying highly connected data.
AWS Neptune, Amazon’s fully managed graph database service, combined with the Amazon Neptune utility for GraphQL, has revolutionized the way developers can approach graph data modeling. By leveraging the expressive power of GraphQL schemas and custom directives, developers can now create clear and intuitive representations of their graph data models. The @relationship directive, in particular, provides a seamless way to define relationships between types, mapping them to the corresponding edges in the graph database. Additionally, the @graphQuery directive allows developers to incorporate custom Gremlin or Cypher queries directly into the schema, enabling efficient traversal and retrieval of data from the graph database. This powerful combination of GraphQL and custom directives has bridged the gap between the GraphQL world and the underlying graph database, making graph data modeling more accessible and collaborative than ever before.
With the Amazon Neptune utility for GraphQL, developers can streamline the process of creating and managing GraphQL APIs backed by Neptune databases. The utility automates the creation of AWS resources, such as AppSync APIs, Lambda functions, and resolvers, based on the provided GraphQL schema or the existing data in the Neptune database. This not only simplifies the development process but also promotes consistency and maintainability, ensuring that the GraphQL API accurately reflects the underlying graph data model.
References
- https://docs.aws.amazon.com/neptune/latest/userguide/tools-graphql.html
- https://github.com/aws/amazon-neptune-for-graphql
- https://github.com/graphql-kit/graphql-voyager
Author: Raghavan Madabusi