LocalStack S3: Your Key to Seamless Apache Spark Development

Introduction
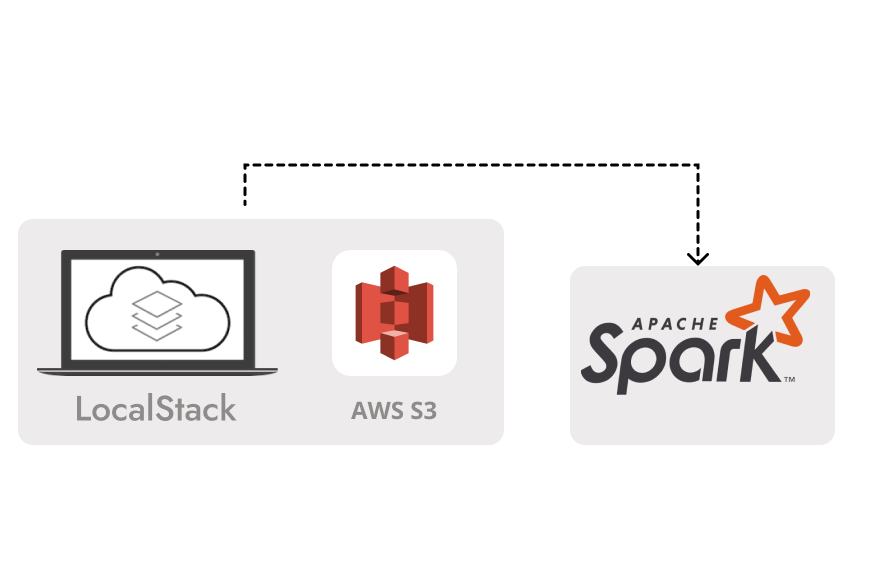
In a world where data rules the day, the importance of validating and testing code before it’s integrated into your operational environment cannot be overstated. Yet, gaining access to Amazon Web Services (AWS) S3 storage from your local development machine can often pose challenges for developers and organizations navigating the complex realm of Big Data. These challenges arise from organizational security policies, access restrictions, and the need to maintain cost-efficiency while ensuring code reliability. LocalStack is a powerful tool that allows you to emulate an AWS S3 environment right on your local development machine, enabling you to conduct robust testing and development without the need for an active connection to the cloud.
This guide takes you on a journey into the world of LocalStack and its integration with Apache Spark, a formidable distributed data processing system. We’ll explore how you can harness the full potential of LocalStack’s S3 emulation to streamline your development and testing processes. But before we delve into the nitty-gritty of setting up LocalStack and Apache Spark, let’s take a moment to understand the core concepts underpinning these technologies, especially if you’re new to the fascinating world of Big Data and cloud services.
Concepts
Apache Spark
Apache Spark is a powerful distributed processing system used for handling Big Data workloads. It leverages in-memory caching and optimized query execution to rapidly analyze data of any size.
Big Data
Big data encompasses vast and diverse collections of structured, unstructured, and semi-structured data that grow exponentially over time. Traditional data management systems struggle to handle the volume, velocity, and variety of such datasets.
Data Lake
A data lake is a central repository for storing massive amounts of raw, unstructured, and structured data in its native format, allowing for a schema-on-read approach.
Data Lake with AWS
AWS-based data lakes often use Amazon S3 as the primary storage platform, benefiting from its unmatched durability, availability, scalability, security, compliance, and audit capabilities.

LocalStack
LocalStack offers a user-friendly test and mocking framework for developing Big Data applications. It sets up a test environment on your local machine, providing functionality identical to actual AWS APIs and services in a cloud environment.

LocalStack Installation and data setup
Installation
Prerequisite:
Before we proceed, make sure you have Docker installed and running. To install LocalStack on macOS, you can use Homebrew
For Mac:
$ brew install localstack/tap/localstack-cliTo verify the installation use:
$ localstack –versionTo start LocalStack, run:
$ localstack start -d
Note: The -d parameter runs LocalStack in the background, and you can use localstack stop to shut it down. LocalStack starts multiple mock AWS services, so check the status of services with:
$ localstack status servicesEnsure that S3 is listed as one of the available services
Creating S3 bucket
Create a test bucket where your program will read and write data:
$ aws s3 mb s3://data-bucket-localstack --endpoint-url http://localhost:4566The localstack mock S3 service runs on port 4566, so use the ‘endpoint-url’ parameter to direct AWS commands to LocalStack
Listing buckets
List S3 buckets using:
$ aws s3 ls --endpoint-url http://localhost:4566You should see the newly created bucket in the list.
Apache Spark Code – Scala
Now let’s dive into Apache Spark code written in Scala. This code will write test data to the local S3 bucket created in the previous step and then read and display the data. We recommend using IntelliJ with SBT as the build tool.
New IntelliJ Project
Create a new project in IntelliJ with the following settings:
Project Name: spark-localstack
Select Language: Scala
Build System: sbt
Scala Version: 2.13.12
(Compatible with the libraries used)
Build Configuration:
In the generated build.sbt file, add the following dependencies:
build.sbt
resolvers += "Maven Repo" at "https://repo1.maven.org/maven2/"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.4.1",
"org.apache.spark" %% "spark-sql" % "3.4.1",
"com.typesafe" % "config" % "1.4.2",
"org.apache.hadoop" % "hadoop-aws" % "3.3.2",
"io.delta" %% "delta-core" % "2.4.0",
"io.delta" %% "delta-contribs" % "2.4.0"
)Application Configuration:
Add three configuration files in the src/main/resources folder: application.conf, application_localstack.conf, and application_prod.conf. These files contain common properties and environment-specific details.
application.conf
app-name=infoservices-spark-appapplication_localstack.conf
include "application.conf"
bucket-name=data-bucket-localstackapplication_prod.conf
include "application.conf"
bucket-name=data-bucket-prodApplication Code:
The application code consists of 2 files:
AppConfig.scala – handles configuration parsing based on the environment and constructs the Config object.
AppConfig.scala
import com.typesafe.config.{Config, ConfigFactory}
object AppConfig {
/** Parses the System Environment ENV. If not set then defaults it to :LOCALSTACK */
val env: String = try {
sys.env("ENV")
} catch {
case _: NoSuchElementException => "LOCALSTACK"
}
/** Loads and parses the application config file corresponding to the environment */
val applicationConf: Config = ConfigFactory.load(s"application_$env.conf")
/** Setting the common and env specific application properties */
val appName: String = applicationConf.getString("app-name")
val bucketName: String = applicationConf.getString("bucket-name")
/** Identifying the S3 scheme which depends on the environment */
val s3Scheme: String =
env match {
case "LOCALSTACK" => "s3a"
case _ => "s3"
}
}SparkApplication.scala – Contains the spark code for working on the sample data that is created on LocalStack emulated AWS S3 service.
SparkApplication.scala
import org.apache.spark.sql.SparkSession
object SparkApplication extends App {
/** Relative path within the bucket where data will be created */
val dataPathKey = "data/org/users/"
/** Full path where data will be created */
val dataPath = s"${AppConfig.s3Scheme}://${AppConfig.bucketName}/$dataPathKey"
/** Get Spark Session */
val spark = buildSparkSession()
spark.sparkContext.setLogLevel("ERROR")
/** Write test data */
writeData()
/** Read and display test data */
readData()
/**
* Reads the data from the configured dataPath and displays it on console
*/
def readData(): Unit = {
val read = spark.read.format("delta").load(dataPath)
read.show(truncate = false)
}
/**
* Writes test data at the configured dataPath
*/
def writeData(): Unit = {
import spark.sqlContext.implicits._
val columns = Array ("id", "name", "gender", "age")
val dataFrame = spark.sparkContext.parallelize (Seq (
(1, "Jason Hive", "m", 54),
(2, "Jamie Day", "f", 42),
(3, "Nita Day", "f", 52),
(4, "John Wick", "m", 32)
) ).toDF (columns: _*)
dataFrame.write.format ("delta").mode ("overwrite").save (dataPath)
}
/**
* Builds a SparkSession based on the selected environment
* @return
*/
def buildSparkSession(): SparkSession = {
val builder = SparkSession.builder()
.appName(AppConfig.appName)
// For using Delta Format or Delta Tables
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
AppConfig.env match {
case "LOCALSTACK" => {
builder
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider")
.config("spark.hadoop.fs.s3a.access.key", "dummy") //For LocalStack, spark needs a dummy value. No need to configure it
.config("spark.hadoop.fs.s3a.secret.key", "dummy") //For LocalStack, spark needs a dummy value. No need to configure it
.config("spark.hadoop.fs.s3a.path.style.access", "true")
.config("spark.hadoop.fs.s3a.endpoint", "http://localhost:4566") //LocalStack S3 Endpoint
.config("spark.master", "local") //Local Spark
.getOrCreate()
}
case _ =>
builder.getOrCreate()
}
}
}Running the Application:
Before running the application, set the environment variable ENV to “LOCALSTACK” to execute the application in local mode. If you don’t set it, the default mode will be “LOCALSTACK.”

The application first writes data to the configured location and then reads and displays the data, all within a virtual S3 bucket emulated by LocalStack on your local machine, without connecting to the real-world AWS S3 service in the cloud.
The output will be as shown below:

Conclusion
In this guide, we’ve demonstrated how you can test your Big Data applications without the need to connect to AWS S3 in the cloud, thanks to LocalStack. This versatile tool extends beyond emulating S3 and provides mock services for various AWS offerings, simplifying development and testing efforts while reducing costs.
Author: Taher Ahmed