Multi-tenant Cross-cluster Search on AWS

Here’s how we have architected a cross-cluster multi-tenant Elasticsearch on AWS in one of our engagements
AWS Elasticsearch
is a fully managed service that makes it simple to deploy, scale, monitor and secure Elasticsearch in AWS
Elasticsearch is primarily used for search, text analytics and log aggregation
What is OpenSearch?
Early in Jan 2021, Elastic announced their software licensing strategy, and will not release new versions of Elasticsearch and Kibana under the Apache License
In order to ensure open source versions of both packages remain available, AWS stepped up to create and maintain Apache licensed fork of Elasticsearch and Kibana
Early April 2021, AWS introduced the OpenSearch project, a community-driven, open source fork of Elasticsearch and Kibana. So, watch out more as AWS will rename their existing Amazon Elasticsearch service to Amazon OpenSearch
With that backdrop aside, lets focus on the purpose of this blog.
Client Problem Statement
Proactively monitor applications and infrastructure using data distributed across logs, infrastructure and multiple AWS accounts to find performance issues faster and improve operational health using AWS Elasticsearch
Sound’s so familiar? Yes, this isn’t a rocket science till we consider the following challenges:
- Multiple AWS accounts will have different resource usage and patterns and they generate logs at different pace
- Pooled/hybrid Elasticsearch domain multi-tenancy for all AWS accounts will have unbalanced resource usage
- Adding, removing or merging new AWS accounts might impact the capacity of the existing Elasticsearch domain
- Providing granular ACL for different AWS account users in the centralized Elasticsearch at index, document and field level is hard
- Operations team can’t have centralized place to look at multiple AWS accounts log data and have to hop on to individual siloed tenants
Solution
Cross-cluster Elasticsearch enables to perform searches, aggregations, and visualizations across multiple AWS Elasticsearch domains with a single query.
This will enable to separate heterogeneous workloads and store different indices on different domains while still being able to query across all domains within a single request
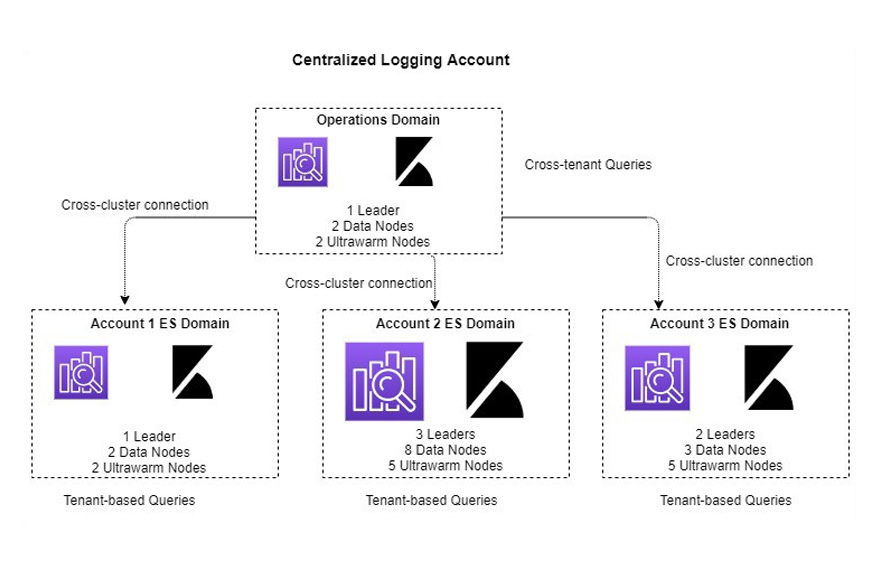
Cross-cluster Elasticsearch Architecture

- Each AWS accounts log data is stored in their respective tenant Elasticsearch domain
- Different Elasticsearch domains are of different instance types and counts depending their usage patterns
- Operations team Elasticsearch domain connects to 3 different domains and can perform federated query in single place
- New Elasticsearch domains can be added when a new AWS account is created
Cross-cluster search limits
- Can’t connect to self-managed Elasticsearch clusters
- Can’t connect to domains in different regions
- A domain can have a maximum of 20 outgoing & incoming connections
- Version should be v6.7+
- For more detailed limitations, refer https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/cross-cluster-search.html#cross-cluster-search-limitations
Author: Raghavan Madabusi