AWS Streaming Showdown: Understanding the Streaming Options


The value of insights derived from data diminishes rapidly over time, making speed a paramount business objective. Streaming data processing emerges as the solution, enabling businesses to instantly extract and act on insights, enhancing the customer experience.
Traditional batch processing falls short in offering real-time solutions like risk mitigation or immediate customer authentication. A delay in action can not only tarnish the customer experience but also be challenging to rectify. Conversely, real-time data actions can bolster fraud prevention measures and amplify customer loyalty. Delayed data can stifle a company’s growth potential.
Here are some practical applications of streaming data:
- Fraud Detection: Streaming data can identify suspicious activities by analyzing transaction patterns and anomalies instantly.
- Enhancing Online Customer Experience: Real-time streaming analytics help online businesses adapt features on their platforms, responding to market dynamics, boosting sales, and elevating user satisfaction.
- IoT Analytics: The IoT domain leverages streaming data to monitor devices and systems in real-time, initiating actions based on specific events.
- Financial Trading: The finance sector uses streaming data to monitor market movements, analyze trade patterns, and make instantaneous decisions.
- Social Media Analysis: Streaming data provides real-time insights into social media trends, sentiments, and behavioral patterns.
- Supply Chain Oversight: Real-time data aids in monitoring logistics, ensuring smooth supply chain operations, and optimizing resource allocation.
- Telecom Monitoring: In telecommunications, streaming data is crucial for real-time network traffic analysis, optimization, and troubleshooting.
- Traffic Regulation: Streaming data offers insights into traffic patterns, aiding in traffic management and congestion reduction.
AWS steps into this arena with Amazon Kinesis, a serverless solution for streaming data processing. Additionally, Kafka extends this capability via Amazon Managed Streaming for Apache Kafka (MSK)
Harnessing Real-time Insights with Amazon Kinesis
Amazon Kinesis stands as a pivotal cloud solution, empowering enterprises to capture, process, and interpret streaming data in real-time. This not only unlocks actionable insights but also facilitates swift decision-making. Kinesis is adept at handling vast streams of data, making it a cost-effective choice for applications with specific needs. From video streams and application logs to IoT signals, Kinesis can ingest a myriad of data types, setting the stage for analytics, machine learning, and more.
One of Kinesis’s strengths is its ability to process data on-the-fly, eliminating the wait for data accumulation. It offers four distinct, fully managed solutions tailored for real-time data collection, processing, and analysis. Let’s delve deeper into what Kinesis brings to the table.
Amazon Kinesis Data Streams (KDS)
Amazon KDS is adept at capturing real-time data, offering a platform to craft custom applications for immediate data processing using renowned stream processing frameworks. It ensures data integrity by maintaining the sequence of data intake and offers flexibility in data processing, making it ideal for iterative analysis or debugging. By default, KDS holds data for a day, but this can be extended up to a week, with an option for a year-long retention.
Think of KDS’s data shard as a conduit for data flow. The more data you have, the more conduits you’ll need. Each shard can accommodate 1 MB or 1,000 records of incoming data every second. On the flip side, data extraction from a shard can go up to 2 MB or 5 reads every second. With KDS, data latency can be as low as 200 ms, but with the Enhanced Fan-Out (EFO) model, this can be reduced to a mere 70 ms.
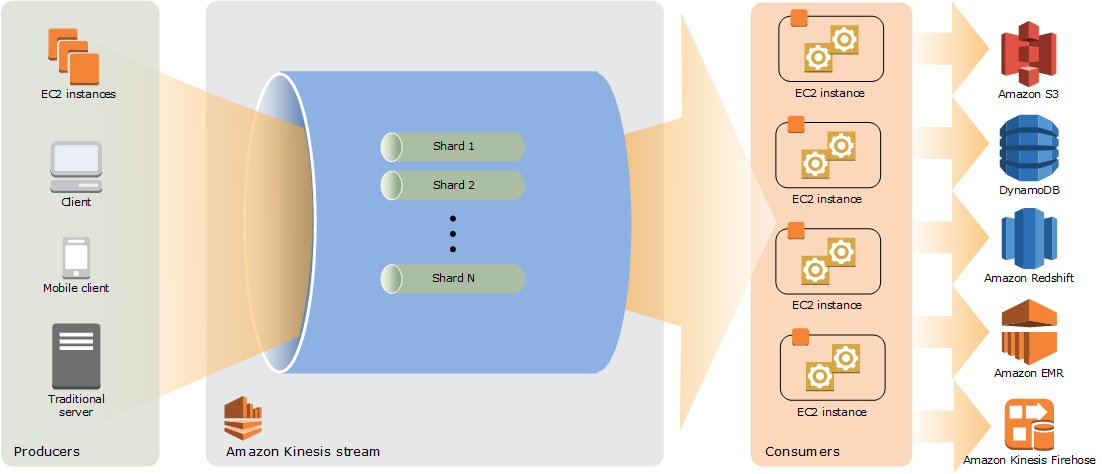
Courtesy: https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html
Recent enhancements in 2021 include the option for long-term data retention, spanning up to a year in KDS. Additionally, AWS introduced auto-scaling capabilities to adapt to fluctuating data volumes, ensuring consistent availability and fault tolerance.
Amazon Kinesis Data Firehose (KDF)
Amazon KDF stands out as a hands-off solution to capture, transform, and channel data streams directly into AWS storage and analysis tools like Amazon S3, Redshift, Elasticsearch, and even third-party tools like Splunk. Its serverless nature ensures hassle-free scalability and zero maintenance. KDF can instantly adapt data formats, making real-time analytics a breeze. Moreover, it now supports data delivery to any HTTP endpoint, including popular platforms like Datadog, Sumo Logic, and MongoDB.
Similarly, in the realm of IoT, KDF can process vast amounts of sensor data, storing it efficiently for predictive analysis. This can lead to proactive maintenance strategies, boosting operational efficiency.
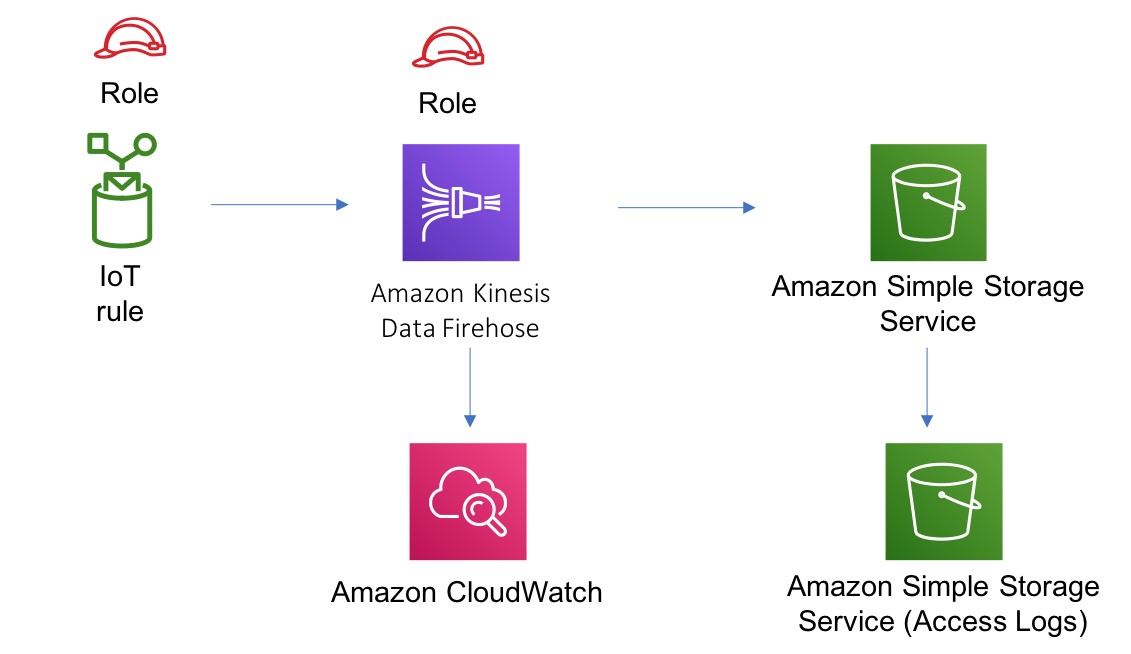
Courtesy: https://docs.aws.amazon.com/solutions/latest/constructs/aws-iot-kinesisfirehose-s3.html
In essence, KDF’s real-time processing capabilities enable businesses to act swiftly, optimizing both operations and customer interactions.
Amazon Kinesis Data Analytics (KDA)
Amazon KDA stands as a beacon for real-time data stream analysis, leveraging the power of SQL and Apache Flink applications. It boasts a suite of built-in functions tailored for real-time data filtration, aggregation, and transformation. With its rapid processing capabilities, KDA ensures that data insights are gleaned and acted upon as they emerge.
KDA Studio, a web-centric interface, offers a playground for users to visually craft, debug, and test KDA applications. It’s equipped with tools like an SQL editor, a code editor, and a debugger, streamlining the analytics application development process. Moreover, users can employ KDA Studio’s interactive mode to scrutinize streaming data, execute impromptu queries, and employ basic chart visualizations for data representation.
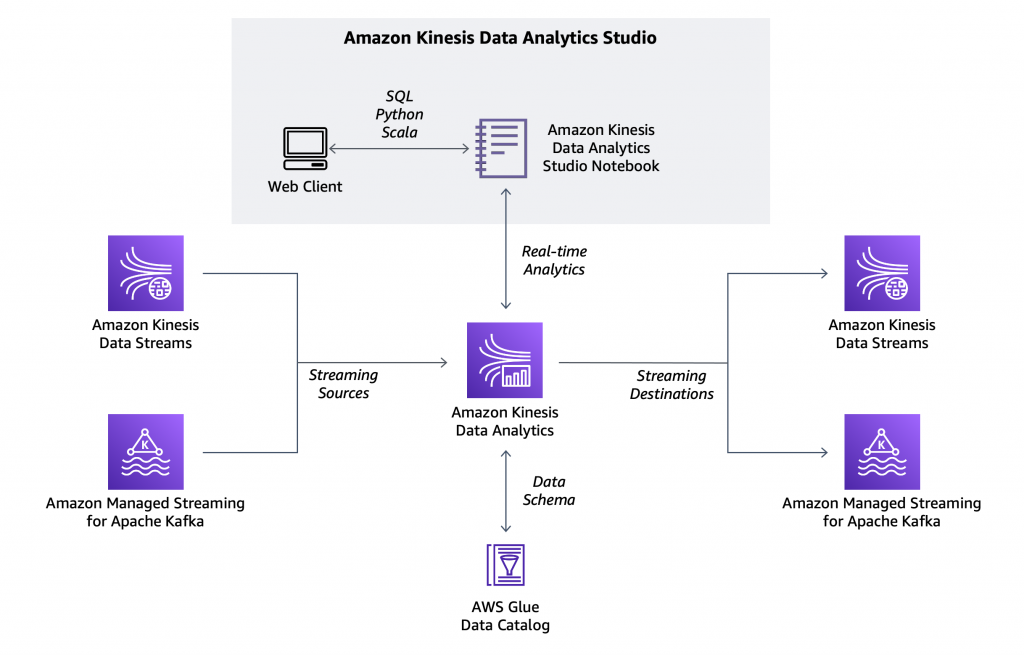
For those inclined towards Java or seeking more intricate applications, KDA extends support for Apache Flink. This integration brings forth benefits such as:
- Effortless Programming: Intuitive and adaptable APIs expedite application development.
- Peak Performance: Leveraging in-memory computing ensures swift processing and high data intake.
- Stateful Processing: Guarantees data integrity with its exactly-once processing mechanism.
KDA seamlessly integrates with Amazon KDS, KDF, and MSK, facilitating real-time data processing and analysis. It’s built atop Apache Flink, renowned for its low-latency processing and high-throughput capabilities. Furthermore, KDA can accommodate data from diverse sources, allowing simultaneous processing with Kinesis data.
Amazon Kinesis Video Streams (KVS)
Another feather in Kinesis’s cap is the Amazon Kinesis Video Streams (KVS), tailored for secure video streaming from IoT devices to AWS, catering to analytics, machine learning, and other computational needs. This is particularly advantageous for media streaming and surveillance video data processing.
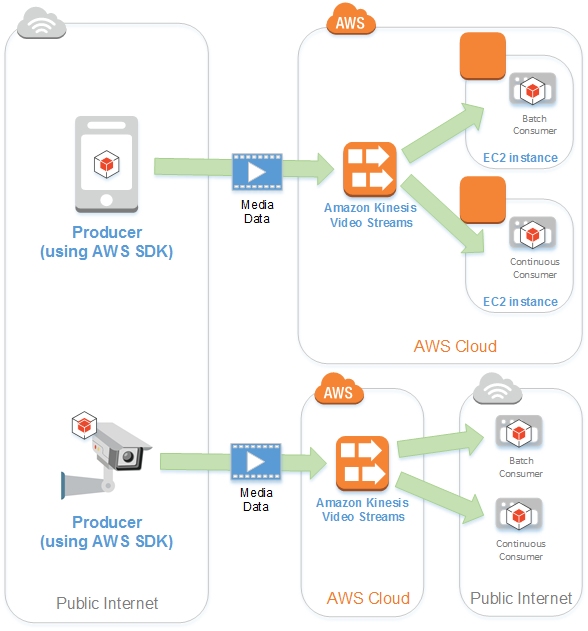
Courtersy: https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/how-it-works.html
Amazon Managed Streaming with Apache Kafka (MSK):
Apache Kafka, a renowned open-source platform, is pivotal for crafting real-time data pipelines and applications. However, its management in a production environment can be intricate, necessitating meticulous planning and continuous upkeep. This includes provisioning servers, manual configurations, and ensuring the servers’ reliability and performance.
Amazon MSK emerges as a solution, offering a fully managed service that lets users harness Apache Kafka’s capabilities without the overhead of infrastructure management. With MSK, AWS shoulders tasks like server maintenance, patching, and ensuring high availability. This allows users to concentrate on their applications and make the most of Kafka’s real-time, high-throughput, and fault-tolerant streaming.
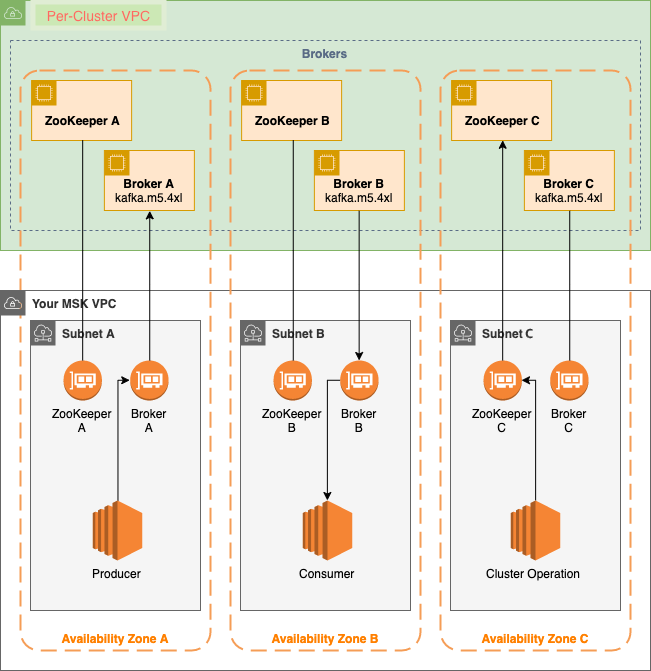
Courtersy: https://docs.aws.amazon.com/msk/latest/developerguide/what-is-msk.html
Key Features of Amazon MSK:
- MSK Cluster Architecture: MSK ensures users can focus on applications rather than infrastructure. It oversees Kafka cluster provisioning and offers features like auto-scaling and monitoring. The architecture comprises:
- Kafka Clusters: These are groups of EC2 instances running Apache Kafka. They can be scaled according to processing and storage needs.
- Zookeeper: Used by Kafka for metadata storage and broker coordination.
- Producers and Consumers: Producers generate and send data to Kafka clusters, while consumers receive and process this data.
- Data Storage: Data is stored in topics, partitioned and replicated across the cluster’s Kafka brokers.
- Networking: MSK employs Amazon VPC for a secure network environment. Users can define the VPC, subnets, and security groups during MSK cluster creation.
- Real-time Data Processing: MSK can be pivotal in sectors like healthcare, where real-time data processing can enhance patient care. For instance, wearable device data can notify caregivers promptly in emergencies.
- MSK Serverless: Introduced at re:Invent 2021, this offering allows users to run Kafka clusters without fussing over cluster capacity. It scales instantly, ensuring users only pay for the data they stream and retain. AWS MSK Serverless GA released in 2022.
In essence, Amazon MSK simplifies the Kafka experience, letting businesses focus on deriving value from their data streams.
Streamlining Data Cataloging with AWS Glue Schema Registry (GSR)
Data streaming technologies, such as Amazon MSK, Apache Kafka, and Amazon Kinesis, are pivotal in various sectors, from finance to retail. They capture and distribute data from diverse sources, offering a robust data transport layer. This layer decouples data-producing applications from real-time analytics and machine learning processors, enhancing scalability, flexibility, and real-time responsiveness. However, the challenge lies in coordinating data formats and structures across multiple systems managed by different teams.
Enter AWS Glue Schema Registry (GSR), AWS’s solution to the complexities of cataloging streaming data. GSR centralizes schema management, offering tools and APIs for schema creation, modification, and versioning. It addresses the challenges of continuous data ingestion in multiple formats. Key features include:
- Schema Discovery: Extract and identify schemas directly from data sources.
- Schema Validation: Ensure data records align with stored schemas.
- Integration with AWS Services: GSR complements other AWS Glue services, like AWS Glue ETL jobs and AWS Glue DataBrew, facilitating the creation of data pipelines with standardized schemas. It also integrates with Amazon KDS and Amazon S3, ensuring data quality and integrity.
- Schema Enforcement: GSR proactively prevents issues arising from schema changes, enhancing developer productivity. It enforces schemas at the data production stage, ensuring consistency before data is sent downstream. Users can tailor schema enforcement using one of the eight compatibility modes, such as Backward, Forward, or Full.
- Efficient Serialization: GSR’s open-source serializers enable compact binary and compressed data serialization, leading to cost savings by reducing data transfer and storage needs compared to uncompressed JSON.
In essence, AWS GSR simplifies the intricacies of streaming data cataloging, ensuring seamless data coordination and quality across systems.
How to Choose between Amazon MSK vs. Amazon Kinesis
| Feature/Aspect | Amazon MSK | Amazon Kinesis |
| Setup & Configuration | Decide on clusters, brokers per cluster, topics per broker, and partitions per topic. | Decide on the number of data streams and shards per stream. |
| Cost Model | Operates under the cluster provision model, generally higher cost. | Throughput provision model, often lower cost as you pay only for the data you use. |
| Scalability | Can increase the number of partitions; decreasing is not possible. | Can both increase and decrease the number of shards. |
| Integration with AWS Services | Integrates with a few AWS services, such as KDA for Apache Flink. | Fully integrates with many AWS services like Lambda, KDA, and more. |
| Throughput Limitations | No limit on throughput. | Throughput scales with shards, supporting up to 1 MB payloads. |
| Open Source | Yes | No |
| Latency | Typically offers lower latency due to its distributed nature. | Might have slightly higher latency compared to MSK, especially when scaling. |
| Use Cases | More suitable for complex, large-scale applications requiring granular control over streaming. | Ideal for quick setups, and applications that require tight AWS integration. |
| Maintenance & Management | Requires more hands-on management and maintenance. | More managed by AWS, reducing operational overhead. |
| Data Retention | Longer data retention capabilities. | Typically used for real-time processing with shorter data retention. |
| Community & Ecosystem | Benefits from the vast Kafka community and ecosystem. | Primarily supported by AWS, but has a growing community. |
Conclusion
Navigating the world of data streaming can be intricate, especially when choosing between Amazon MSK and Amazon Kinesis. Both platforms offer unique advantages tailored to specific needs. While Amazon MSK, rooted in the open-source Apache Kafka ecosystem, provides granular control and is ideal for complex, large-scale applications, Amazon Kinesis shines in its seamless integration with AWS services, making it perfect for real-time processing tasks and applications desiring tight AWS integration.
It’s crucial to understand the nuances of each service, from cost implications to scalability and integration capabilities. As we’ve explored, MSK requires a more hands-on approach, but its extensive Kafka community support can be invaluable. On the other hand, Kinesis, with its managed nature, reduces operational overhead, making it a go-to for businesses looking for a more straightforward streaming solution.
Author: Raghavan Madabusi