Reference Architecture - Serverless Interactive Analytics with Amazon Athena and AWS Glue

Context
Serverless applications gained a huge adaption over last few years with AWS offering services like AWS APIGateway, AppSync, Lamda, Amplify etc. We have seen earlier how to develop serverless web applications using Amplify in our previous blog “Developing Serverless applications with AWS Amplify”. In this blog, we discuss how to extend previous architecture to perform quick “Interactive Analytics” without provisioning any infrastructure and how to integrate it with web applications.
Amazon Athena
Amazon Athena is an interactive and serverless query service to analyse data in Amazon S3 using standard SQL. There is no infrastructure to manage and users only pay for the queries they execute.
AWS Glue
AWS Glue is a serverless data integration service that is used to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides rich data integration capabilities to catalogue the data from sources like S3, CloudWatch Logs, DynamoDB, DocumentDB, Redshift, HBase, Redis, OpenSearch, Timestream etc. “AWS Glue Data Catalog” quickly discovers and searches across multiple AWS data sets without moving the data. The data, that is catalogued, is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
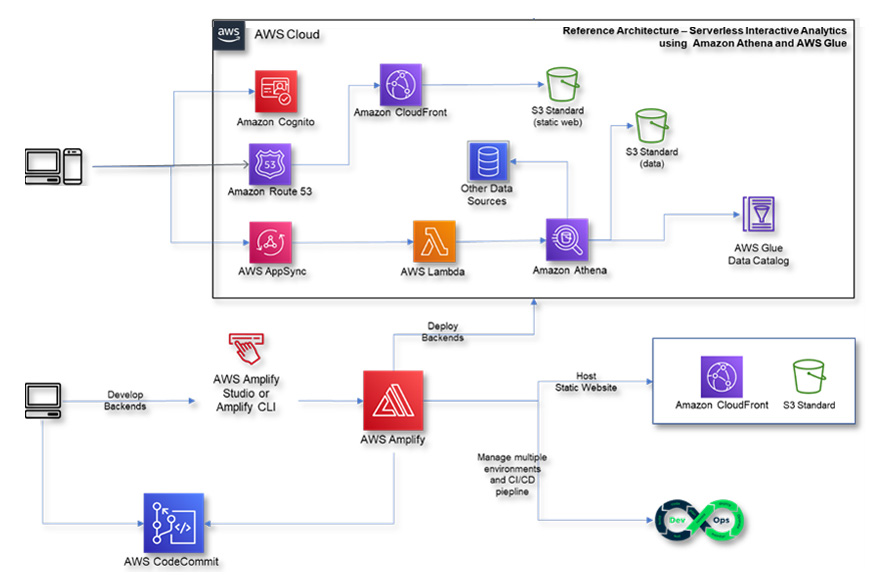
Reference Architecture
Below diagram depicts a Reference Architecture to implement serverless interactive analytics applications using “Amazon Athena” and “AWS Glue”. Users can use AWS console to directly query catalogued data sources using standard SQL queries. But this Reference Architecture details about fetching data using AWS Athena from a web application.

This Architecture involves using AWS Lambda querying Amazon Athena using SQL queries. Lambda can be invoked from AppSync (or API Gateway) to fetch data from a web application.
Here are high-level steps in implementing this Reference Architecture:
- Upload data to S3
While this can be done manually, “AWS Glue ETL” can be used to move the data into S3 from different data sources. AWS Glue ETL helps building data integrations visually from different data sources like Redshift, MYSQL, Oracle, DynamoDB, AWS Glue Data Catalog etc. “AWS Glue” also helps run queries across data sources using SQL joins.
Consider storing data in Parquet/ORC format instead of storing data in text/csv format and partition the data in S3 (e.g store it by region, date etc) for fast query performance.
- Create Athena Data Source
Create a data source using “S3 – AWS Glue Data Catalog” option from AWS Athena interface and use “Create a crawler in AWS Glue” choice while creating the data source.

“Create a crawler in AWS Glue” option creates a “AWS Glue Crawler” that connects to a data store, determines the schema of the given data, and then creates metadata tables (table and column names) in the data catalog. This metadata is used to query data using SQL queries.
SQL queries can be executed directly from Athena “Query Editor”. Below is a sample query execution from AWS console:

- Create a Lambda function to invoke SQL queries
Below is a sample python code that can be used from a Lambda function to execute an Athena SQL query.
- Create an API for using Lambda
Make above lambda function available to web applications using either “Amazon API Gateway” or “AWS AppSync”
import boto3
def lambda_handler(event, context):
client = boto3.client('athena')
response = client. start_query_execution(
QueryString='select year, sum(revenue) from info_services_sample_athena_data group by year',
QueryExecutionContext={
'Database': 'sales',
'Catalog': 'AwsDataCatalog'
},
ResultConfiguration={
'OutputLocation': 's3://aws-research-infoservices-athena-output/',
}
)
query_execution_id = response['QueryExecutionId']
print(query_execution_id)
while True:
query_status = client.get_query_execution(QueryExecutionId=query_execution_id)
executionStatus = query_status['QueryExecution']['Status']['State']
if executionStatus == 'SUCCEEDED':
break
result = client.get_query_results(QueryExecutionId=query_execution_id)
return {
'statusCode': 200,
'body': result
}
Why AWS Athena?
There are many options in AWS to suit different analytical use cases. Amazon Redshift can be used for enterprise reporting and business intelligence workloads, that involve complex SQL with multiple joins and sub-queries. Amazon EMR can be used to host highly distributed processing frameworks such as Hadoop, Spark, and Presto and these can be used to process huge amount of data. But these options involve setting up the infrastructure and caters to different use cases. AWS Athena using Amazon Glue can be used to quickly start querying data within minutes without setting up any separate Infrastructure.