Databricks Data Intelligence Platform: 5 Core Capabilities That Set It Apart
Redefining data intelligence with unified, AI-driven capabilities.
Introduction: From Lakehouse to Intelligence
Databricks has long been recognized for pioneering the Lakehouse architecture — combining the reliability of data warehouses with the scalability of data lakes. But in 2024, Databricks introduced a significant evolution: a shift from being a “lakehouse platform” to becoming a Data Intelligence Platform.
This rebranding isn’t just cosmetic. It marks a strategic shift to address the complex intersection of AI, governance, semantics, and real-time data.
As a Databricks cloud partner who has implemented solutions across sectors like finance, retail, healthcare, and manufacturing, we see this evolution as critical for enterprises aiming to operationalize AI safely and scalably.
What Is a Data Intelligence Platform?
A Data Intelligence Platform goes beyond storage, compute, or pipelines. It is a system that makes enterprise data understandable, trustworthy, and usable by both humans and machines — especially AI agents and LLMs.
Key Characteristics:
- Unified governance across all assets (data, models, notebooks, dashboards)
- Semantic context via metadata, lineage, and usage patterns
- Built-in support for GenAI and ML workflows
- Streaming-native architecture for real-time analytics
- Interoperability with other data engines and platforms
In simple terms, a data intelligence platform doesn’t just manage data — it understands it and prepares it for AI-driven use cases.
Here’s our technical breakdown of the five critical features that define a true data intelligence platform — and how Databricks leads in each.
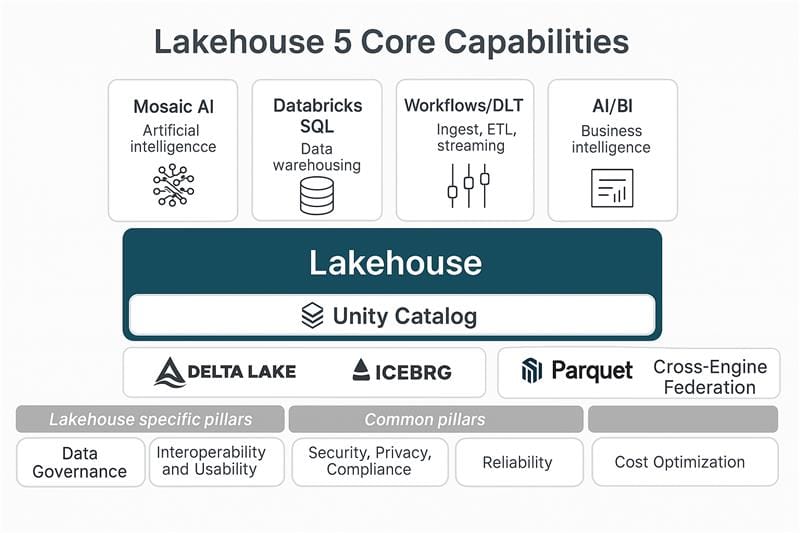
1. Unified Governance at the Metadata Layer: Unity Catalog
In a distributed enterprise, governance is not optional — it must be embedded at the metadata layer, not just enforced through IAM roles or per-table ACLs.
Why It Matters Technically:
- Data, ML models, and dashboards need consistent lineage and auditability.
- Fine-grained access should operate across cloud boundaries and data types.
- Governance policies must scale across services and personas — from Spark jobs to BI tools.
Databricks Approach:
Unity Catalog is a centralized metadata service that governs access across Delta Lake, MLflow models, and dashboards. Technically, it:
- Provides column-, row-, and tag-level access policies.
- Tracks end-to-end lineage — SQL, Python, notebooks, and ML assets.
- Supports dynamic views and attribute-based access control (ABAC).
Unity Catalog now supports model-level access control, making it easier to enforce compliance across AI workflows.
2. Semantic Layer and Natural Language Intelligence: LakehouseIQ
As LLMs integrate into enterprise systems, traditional metadata tagging is no longer enough. You need semantic context — not just schemas.
Why It Matters Technically:
- Analysts and LLM agents need a semantic map of enterprise data.
- Query generation and AI reasoning depend on usage patterns, lineage, and context.
- Semantic understanding must work with structured + unstructured data.
Databricks Innovation:
LakehouseIQ introduces an LLM-native semantic layer. It:
- Learns from query logs, lineage, and schema relationships.
- Enables natural language querying and question answering over cataloged assets.
- Is context-sensitive — tuned to each enterprise’s usage patterns.
This enables use cases like:
- Self-service analytics without writing SQL.
- Autonomous agents using LangChain + LakehouseIQ for data-driven RAG apps.

3. Native AI and Model Lifecycle Integration: Mosaic AI + MLflow
A true data intelligence platform must integrate AI development, deployment, and monitoring — not just offer storage and compute.
Why It Matters Technically:
- GenAI models require high-performance feature pipelines, real-time inference, and evaluation.
- MLOps should be first-class, not stitched together through plugins.
- Security and compliance must also cover model inputs and outputs.
Databricks Stack:
- Mosaic AI Training: Fine-tune open-source LLMs like MPT, Llama 2 using enterprise data.
- Mosaic AI Gateway: Manage third-party and custom models behind a unified API, complete with rate-limiting and observability.
- MLflow 2.x: Integrated experiment tracking, model registry, and evaluation.
Advanced Features:
- Model Serving with GPU support
- Vector Search (GA) with integrated ANN indexing and strong Delta Lake support
- RAG pipelines with LangChain + LakehouseFS
See: Building with LLMs Guide
4. Streaming-First Architecture: Delta Live Tables + Auto Loader
Streaming is no longer a “real-time add-on” — it’s foundational to modern intelligence platforms.
Why It Matters Technically:
- Event-driven architectures require exactly-once processing with low latency.
- Streaming ETL must support stateful transformations, orchestration, and monitoring.
- Lakehouse ingestion pipelines should auto-scale based on file size, not just trigger intervals.
Databricks Tools:
- Auto Loader: Scalable file ingestion from cloud object stores using notification services and checkpointing.
- Delta Live Tables (DLT): Declarative ETL framework with:
- Built-in data quality checks (expectations)
- Continuous and triggered modes
- Schema evolution handling
Tip: DLT now supports orchestrated streaming DAGs that can serve both ML pipelines and BI dashboards.
5. Open Data Sharing + Cross-Engine Federation
You can’t build intelligence in a silo. A modern platform must interoperate with external warehouses, tools, and vendors — without copying data.
Why It Matters Technically:
- Data mesh and decentralized architectures demand secure data exchange.
- Enterprises need to query external systems (e.g., Snowflake, BigQuery) without ingestion delays.
- Collaboration with vendors or partners often requires controlled sharing of assets.
Databricks Tools:
- Delta Sharing: Open protocol for sharing Delta Lake data across orgs/clouds.
- Lakehouse Federation: Query external data warehouses from within Databricks (Postgres, Redshift, Snowflake, etc.).
Combined with Unity Catalog, these tools allow:
- Cross-platform lineage
- Role-based access enforcement across domains
- Live data access across suppliers, partners, and subsidiaries
Summary: What Sets a Data Intelligence Platform Apart?
| Feature | Databricks Toolchain | Technical Value |
|---|---|---|
| Unified Governance | Unity Catalog | Fine-grained, cross-cloud access control + lineage |
| Semantic Intelligence Layer | LakehouseIQ | Contextual natural language + query optimization via usage learning |
| Built-in AI & Model Lifecycle | MLflow + Mosaic AI | Fine-tune, serve, evaluate, and monitor models at scale |
| Streaming-First ETL | Delta Live Tables + Auto Loader | Declarative + continuous pipelines with auto-scaling and quality enforcement |
| Interoperability & Federation | Delta Sharing + Lakehouse Federation | Query + share data across platforms securely and seamlessly |

Final Thoughts
The term “Data Intelligence Platform” isn’t just a marketing label — it reflects a real shift in how governance, semantics, and AI must converge into a unified data layer. Databricks is leading this evolution by not just integrating components, but deeply embedding intelligence into every layer — from ingestion to model serving.
If you're evaluating Databricks or modernizing your stack, remember: this is no longer about a lakehouse vs. warehouse debate. It’s about intelligence-first architecture.

FAQ'S
1. What is the difference between a Lakehouse Platform and a Data Intelligence Platform?
A Lakehouse unifies data lakes and warehouses, while a Data Intelligence Platform adds governance, semantics, and AI-readiness, making data usable for both humans and machines.
2. How does Unity Catalog enhance governance in Databricks?
Unity Catalog offers fine-grained access control, end-to-end lineage, and cross-cloud policy enforcement across data, ML models, and analytics assets.
3. What role does LakehouseIQ play in enabling AI and LLMs?
LakehouseIQ provides a semantic layer that enables natural language querying, contextual understanding, and LLM integration for AI-driven decision-making.
4. Can Databricks handle real-time data processing?
Absolutely. With tools like Delta Live Tables and Auto Loader, Databricks is designed for streaming-first ETL, handling continuous data flows with scale and reliability.
5. How does Databricks support model training and deployment?
Through Mosaic AI and MLflow, Databricks offers a complete suite for training, fine-tuning, serving, and monitoring AI/ML models at scale.