Building Real-Time Intelligence: How Lakebase Drives AI and Agents

Imagine this: a fraud-detection agent sees a suspicious transaction and, within 10 milliseconds, fetches the latest features, cross-checks a user’s history, and decides whether to block or allow before the card is swiped again. That kind of responsiveness is what modern AI-native applications demand, yet most data stacks weren’t built for it.
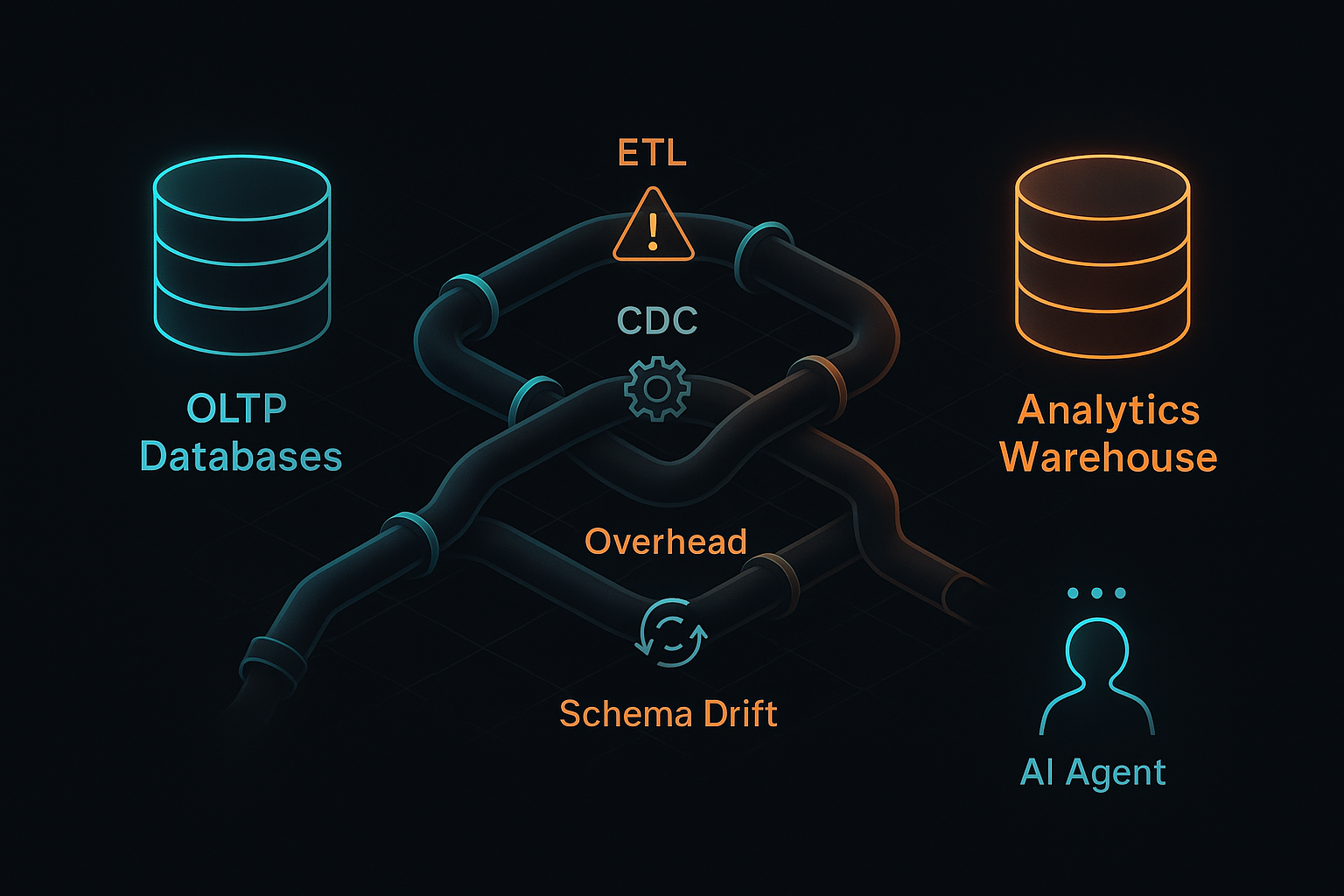
Traditional architectures split transactional systems (fast reads/writes for apps) and analytics systems (batch processing for reports and ML). Data shuffles between them via ETL or CDC, introducing lag and complexity. For AI agents that must act on the freshest signals, this gap becomes the bottleneck.
Lakebase, an operational database integrated into the Databricks Lakehouse, aims to close that gap. It combines serverless operations, Postgres compatibility, and tight governance with features like database branching a compelling mix for real-time AI and agentic workloads. Below, we break down why it matters, how it works, where it shines, and what to watch.

The Problem: OLTP vs. Analytics, and the Cost of the Middle
OLTP systems (e.g., PostgreSQL, MySQL, DynamoDB) excel at low-latency, high-concurrency transactions. Analytics systems (warehouses and lakehouses) excel at aggregations, joins, and large-scale processing.
Keeping them separate forces you to maintain pipelines: ETL, CDC, event streams, and sync jobs. The results:
- Extra latency between “event” and “insight.”
- Operational overhead and more failure points.
- Consistency drift and schema divergence.
- Slower feedback loops for model updates and agent behavior.
Agents exacerbate this because they need:
- Fast feature lookup (sub-10 ms where possible).
- Transactional state (session/context memory, counters, flags).
- Experimentation/branching (try a new policy safely, then merge or roll back).
- Tight feedback loops (predictions generate data that must immediately inform the next decision).
The ideal is a unified substrate where operational state, features, and analytics coexist without constant shuttling.
What Is Lakebase?
Lakebase is a managed, Postgres-compatible operational database that runs serverlessly inside the Databricks platform and integrates deeply with the Lakehouse and Unity Catalog. According to Databricks, Lakebase decouples compute from storage, launches quickly, and scales automatically. It supports familiar SQL tooling and extensions (e.g., pgvector for embeddings), and provides database branching to clone state for safe experiments. Public previews and early commentary also highlight low-latency query performance and governed integration with analytics.
Key capabilities at a glance
- Serverless, autoscaling: Near-instant startup and elastic compute.
- Compute–storage separation: Pay for compute only when you run it.
- Postgres compatibility: Use standard SQL, drivers, and extensions (e.g., pgvector).
- Database branching: Copy-on-write clones of schema + data for tests and sandboxes.
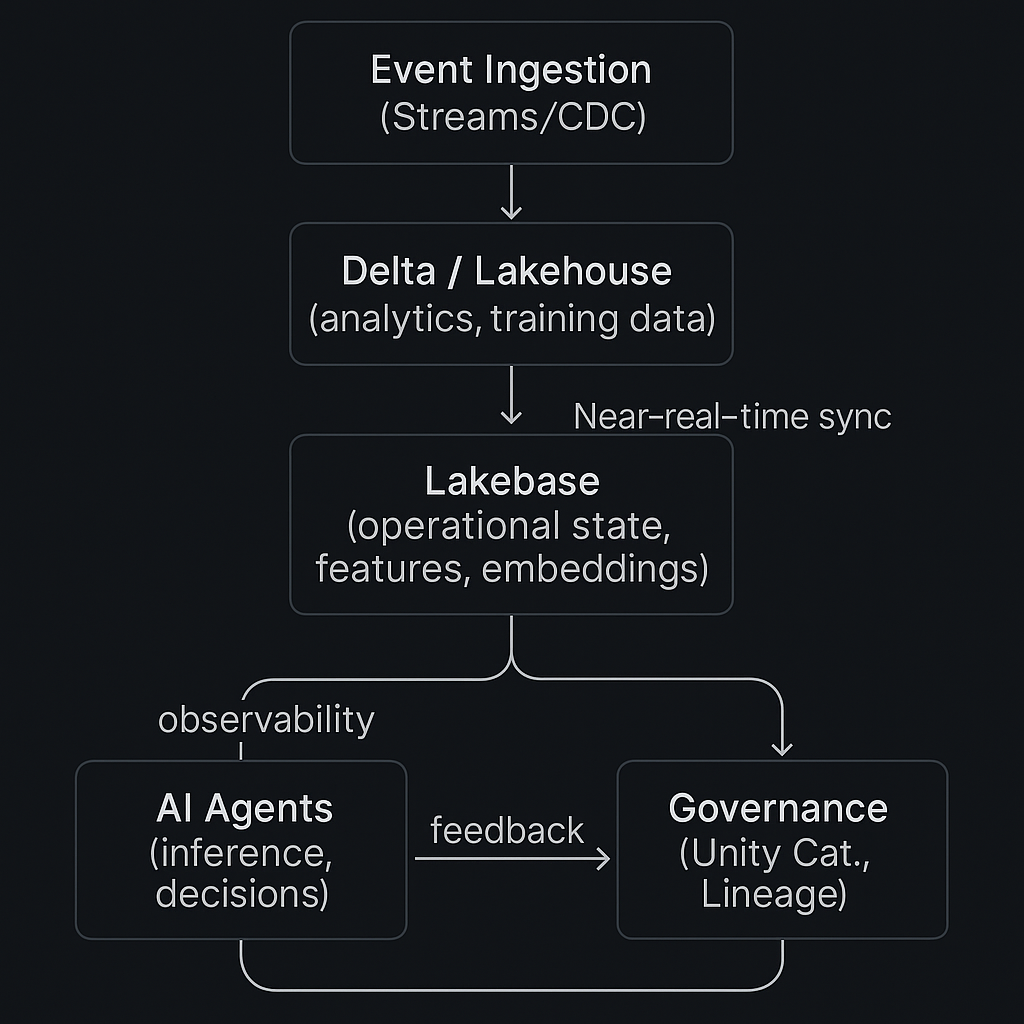
- Lakehouse integration: Near-real-time sync to Delta/Unity Catalog; minimize ad-hoc ETL.
- Governed by design: Access control, lineage, and auditing through Unity Catalog.
- Low latency at scale: Engineered for sub-10 ms responses with high QPS (early reports).
Why this matters: You get an OLTP-grade store inside your analytics and AI platform shrinking the distance between events, features, decisions, and learning.
Official Databricks Lakebase documentation provides deeper insights into configuration, use cases, and scaling models.
How Lakebase Enables Real-Time AI and Agent Workloads
1) Feature Serving for Ultra-Fast Inference
Models frequently need precomputed features (counts, recency, embeddings) at prediction time.
- Keep hot features in Lakebase for single-digit-millisecond access.
- Use pgvector for similarity search and semantic lookups in RAG-style agents.
- Reduce staleness by avoiding cross-system syncs.
According to Databricks, keeping operational features close to analytics and governance improves freshness and simplifies pipelines.
2) Durable Agent Memory and Transactional State
Agents maintain conversation history, session context, and policy flags. Lakebase provides:
- ACID transactions and row-level operations for consistent behavior.
- Indexes for predictable latency under concurrency.
- Fast updates to state as agents act and learn.
3) Safe Experimentation via Database Branching
Testing new prompts, policies, or reward functions on production-like data is risky unless you can branch.
- Spin up a copy-on-write branch to sandbox changes.
- Run A/B or multi-arm experiments without corrupting prod.
- Merge or roll back after evaluation.
Industry write-ups have showcased branching for rapid iteration and debugging in Lakebase-style workflows.
4) A Unified Feedback Loop: OLTP Meets Analytics
Because Lakebase syncs with the Lakehouse:
- Operational events (e.g., agent actions) feed analytics immediately.
- Training data stays fresh; monitoring and evaluation stay tight.
- You avoid a thicket of ETL jobs just to keep models current.
5) Elastic Cost Model for Spiky Agent Traffic
Agent workloads burst launches, seasonality, “viral moments.”
- Autoscaling handles surges; scales down when idle.
- Compute and storage are decoupled for cost control.
- Watch patterns to right-size any steady state.
6) Governance, Security, and Observability
With Unity Catalog and platform-native telemetry:
- Consistent permissions across data, features, and models.
- Lineage and auditing for compliance.
- Performance monitoring to detect drifts, outliers, and hot spots.
Example Use Cases
Conversational agents / copilots Store session context and retrieved embeddings; branch new dialogue strategies safely; measure impact.
Fraud detection & risk Ingest events, fetch features in milliseconds, score risk, and take action then feed decisions back for model improvement.
Real-time personalization & recommendations Update user profiles and behavior counters as they browse; serve next-best actions instantly; retrain with minimal lag.
IoT & predictive maintenance Maintain device state, evaluate anomalies in real time, simulate fixes in a branch, merge validated changes.
Autonomous workflow agents Orchestrate pipelines and business actions with durable state and governed access to enterprise data.
Architecture
Challenges and Considerations
To keep the narrative balanced, it helps to surface trade-offs before best practices.
Availability & Maturity
- Preview/GA status varies by region; confirm what’s supported today.
- Early products may have limits on size, concurrency, or feature coverage vs. long-mature OLTP engines.
Cost & Autoscaling
- Elastic compute is great for bursts, but cost spikes can surprise.
- Profile workloads; set budgets and alerts; consider off-peak throttling.
Performance & Concurrency
- Complex joins or wide scans can add latency schema & index choices matter.
- Contention patterns in agent updates require careful transaction design.
Operations & Recovery
- Validate backup/restore objectives for operational state.
- Plan for observability, tracing, and SLOs from day one.
Platform Coupling
- Deep integration simplifies pipelines but increases vendor coupling.
- Keep abstractions and data export paths in mind.
Best Practices for AI/Agent Workloads on Lakebase
Design for access patterns Model tables and indexes around the exact reads/writes agents perform most.
Keep transactions small Short transactions reduce contention and tail latency.
Use branching intentionally Sandbox new prompts, reward models, or policies; test migrations; rehearse rollbacks.
Leverage pgvector wisely Store embeddings where retrieval + filtering happen together; pre-compute candidates if needed.
Partition and cluster large tables Reduce scans and keep hot data hot; align partitions to query filters.
Cache in the agent Memoize ultra-hot features or results to shave milliseconds.
Monitor scale & spend Instrument P95/P99 latency, QPS, and autoscaling events; alert on anomalies.
Sync smartly Prefer near-real-time sync to Delta over bespoke ETL pipelines when possible.
What to Watch Next
- GA milestones & regional expansion enterprise readiness and SLAs.
- Global replicas & geo-distribution support for worldwide agent deployments.
- Advanced indexing & vector capabilities tighter AI-native retrieval.
- Deeper “agent platform” hooks agents that branch, test, and merge via APIs.
- Managed loops for retraining & A/B turn feedback into continuous improvement.
- Broader ecosystem connectors bridges to search/graph/streaming engines.
Conclusion
The center of gravity for AI apps is shifting from batch analytics to real-time decisions. Lakebase compresses the distance between data, features, and actions by embedding an OLTP-grade store inside the lakehouse, with governance and elasticity built-in. That’s a strong foundation for agents that must perceive, decide, and learn in the moment.

FAQ's
1. How does Lakebase differ from traditional feature stores for AI?
Lakebase unifies feature storage and transactional data within the Lakehouse, eliminating sync delays, enabling real-time updates, and improving AI inference speed through direct, governed access to fresh operational data.
2. Can Lakebase handle multi-region or global agent workloads?
Currently in preview, Lakebase supports region-based deployments. Future roadmap includes global replication for low-latency access and consistency across worldwide AI agent applications and distributed systems.
3. How does Lakebase maintain data consistency during rapid agent updates?
Lakebase uses ACID transactions, ensuring all reads and writes remain consistent even under high concurrency. This makes it reliable for agents performing frequent state changes or session updates.
4. What are some monitoring and alerting tools compatible with Lakebase?
You can integrate Databricks-native observability, Unity Catalog lineage, and external tools like Prometheus or Grafana for latency tracking, error detection, and performance anomaly alerts.
5. How can enterprises optimize cost with Lakebase’s serverless model?
By separating compute from storage, Lakebase charges only for active usage. Organizations can autoscale compute during traffic surges and automatically scale down during idle times to save costs.