Databricks Meets LlamaIndex: Simplifying LLM-Based Data Access

1. Introduction
Organizations generate vast amounts of unstructured data daily, including emails, PDFs, wikis, logs, and various other forms. Traditional machine learning models (LLMs) often struggle to process these data silos effectively at scale due to several challenges, such as latency, governance issues, and token limit constraints. Retrieval-Augmented Generation (RAG) has emerged as a powerful solution to address these hurdles, enabling LLMs to efficiently pull in data from external sources.
While RAG as a concept is transformative, implementing it in a production environment presents its complexities, from data ingestion to effective querying and retrieval. Databricks and LlamaIndex together provide a comprehensive, scalable solution for LLM-powered applications. Businesses can build more effective, secure, and scalable LLM-powered applications by combining Databricks' powerful Data Intelligence Platform with LlamaIndex's flexible data retrieval architecture.
This blog post will explain how Databricks and LlamaIndex work together to simplify LLM-based data access and provide clear guidance for implementing this robust solution.

2. What is LlamaIndex?
LlamaIndex (formerly GPT Index) is an open-source framework designed to handle LLM-based data retrieval and interaction. It is a crucial middle layer that bridges raw data and the LLM. It solves most of the issues with large-scale LLM deployments, particularly in enterprise environments where data is stored in varied formats and systems.
Key Features of LlamaIndex:
- Document Loaders: LlamaIndex can load data from various sources, such as PDFs, websites, or databases, making it versatile across different data systems.
- Node Parsing and Chunking: It intelligently splits data into smaller, more manageable pieces (nodes), allowing for efficient retrieval and processing.
- Indexing: LlamaIndex creates a structured index for data retrieval using vector stores or traditional keyword-based indexing methods.
- Query Engines: With flexible search interfaces, prompt templates, rerankers, and filters, LlamaIndex provides a robust query engine that can return highly relevant results based on specific search queries.
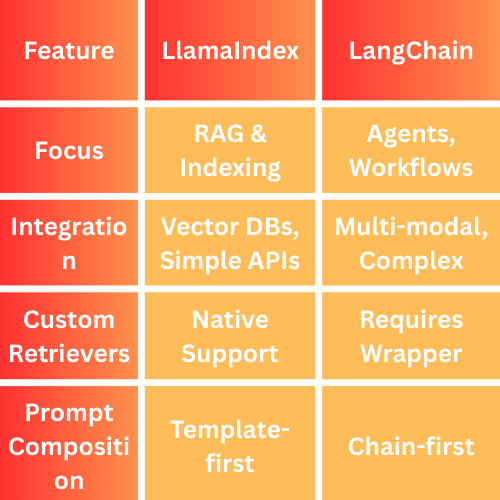
In contrast to LangChain, which is more oriented toward agent-based frameworks and complex workflows, LlamaIndex is purpose-built for RAG and indexing processes, making it more focused and suited for large-scale data access in LLMs.

For more details, check out LlamaIndex’s GitHub repository.
3. Why Databricks for LLM Infrastructure?
While LlamaIndex offers excellent retrieval capabilities, Databricks provides the infrastructure to scale LLM applications to an enterprise level. Databricks is more than just Apache Spark; it's a Data Intelligence Platform that integrates various components required for efficient LLM deployment, including data storage, governance, model lifecycle management, and real-time serving capabilities.
Key Features of Databricks that Enhance LLM Workflows:
- Delta Lake: A high-performance, ACID-compliant storage layer that ensures data consistency and reliability across large datasets, essential for LLM applications where data integrity is crucial.
- Unity Catalog: A powerful feature for data governance that offers fine-grained control over who can access data, making it an essential component for securely managing data used in LLMs.
- MLflow: Databricks’ model lifecycle management solution allows teams to track and monitor machine learning models from experimentation to deployment.
- Databricks Model Serving: The ability to host LLMs in a scalable, real-time environment for low-latency applications.
- Vector Search (GA): Databricks now supports native vector indexing, allowing you to store and query vector embeddings natively within the platform.
These features make Databricks an excellent choice for implementing LLM-powered systems, enabling teams to build scalable, secure, high-performance applications.
For more details, explore the Databricks platform.
4. LlamaIndex + Databricks Architecture
The combination of LlamaIndex and Databricks results in a seamless pipeline for building scalable LLM applications. Here's an overview of the architecture:
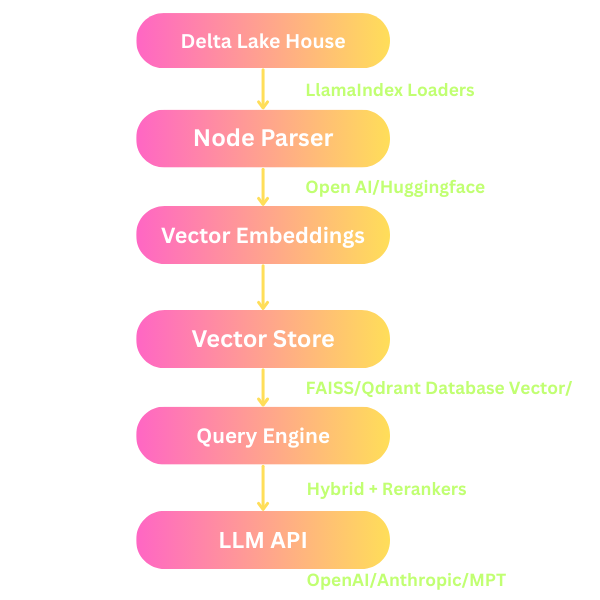
Steps in the Workflow:
- Ingest Data: Use a document loader to bring data from Delta Lake into the LlamaIndex framework.
- Chunking & Embedding: LlamaIndex parses and chunks the data into nodes, creating embeddings using models like OpenAI or HuggingFace.
- Vector Indexing: The chunked data is indexed into a vector store for efficient querying.
- Querying: LlamaIndex’s query engine allows you to retrieve relevant information using hybrid queries or reranking techniques.
- LLM API Interaction: Finally, the LLM is queried to generate insights, summaries, or responses based on the retrieved data.
This architecture ensures that the data flow is scalable and secure, leveraging Databricks' powerful data platform features.
5. Technical Implementation
Now, let’s examine some of the key steps to implementing this architecture, starting with data ingestion, embedding, and querying using the LlamaIndex framework.
a. Ingesting Data from Delta Lake
You can ingest structured and unstructured data stored in Delta Lake and put it into the LlamaIndex system for processing. Here’s a simple example of loading data from Delta Lake:
from llama_index.readers.file.base import SimpleDirectoryReader
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("delta").load("/mnt/data/wiki-pages/")
df.write.mode("overwrite").csv("/tmp/docs")
reader = SimpleDirectoryReader("/tmp/docs")
documents = reader.load_data()
b. Chunking & Embedding
Once data is loaded, the next step is chunking and embedding the content using LlamaIndex’s built-in Node Parser and embedding models.
from llama_index.node_parser import SimpleNodeParser
from llama_index.embeddings import OpenAIEmbedding
nodes = SimpleNodeParser().get_nodes_from_documents(documents)
embed_model = OpenAIEmbedding()
for node in nodes:
node.embedding = embed_model.get_text_embedding(node.text)
c. Creating a Vector Index
After embedding the data, we store it in a Vector Store for efficient search and retrieval.
from llama_index import VectorStoreIndex
index = VectorStoreIndex(nodes)
d. Querying with Filters and Prompts
Now that the data is indexed, we can query it based on user prompts or use specific filters to narrow down the results.
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("Summarize the key security benefits of Unity Catalog")
print(response)
e. Persisting Indexes in Unity Catalog
You can persist the vector indexes in Unity Catalog to ensure your data remains accessible across different clusters and environments.
index.storage_context.persist(persist_dir="/Volumes/company_ai/vector_indexes/wiki")6. LLM Reranking and Response Optimization
To improve the relevance and coherence of the responses generated by LLMs, you can use rerankers and postprocessors from LlamaIndex.
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
query_engine = RetrieverQueryEngine(
retriever=index.as_retriever(),
postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.75)]
)
This ensures that the results returned are relevant and high-coherence, improving the quality of the LLM's responses.
7. Performance & Scalability
With Databricks, you can easily scale your LLM infrastructure. Here are some tips to ensure high performance:
- Leverage Databricks' native vector indexing to efficiently store and retrieve embeddings using Databricks Vector Search
- Run Nightly Jobs: Automate nightly ingestion and processing tasks using Databricks Jobs or Workflows.
- Monitor Performance: Use MLflow for real-time model monitoring and track performance metrics with LLM-Eval tools.
8. Use Cases
The combination of Databricks and LlamaIndex unlocks several use cases for enterprises:
- Internal Enterprise Search: Power internal search engines with real-time, high-quality data retrieval.
- Customer Support Agents: Use RAG to provide customer support chatbots with real-time, accurate data from your knowledge base.
- Domain-Specific Assistants: Build specialized assistants that can access domain-specific data, such as legal or medical knowledge bases.
- Financial RAG Chatbots: Deploy chatbots that can access and summarize large volumes of economic reports in real-time.
9. LlamaIndex vs LangChain
LlamaIndex focuses on connecting LLMs to external data sources through indexing, while LangChain offers a broader framework for building complex, multi-step AI applications using chains of LLM calls and tools.
10. Security & Governance
You can implement stringent access controls and masking for sensitive data with Unity Catalog. Use MLflow or Unity Catalog query history features to log all queries for auditing purposes.
11. Real-world Deployment Patterns
- Real-Time Copilots: Utilize Databricks Model Serving and Webhooks to deliver instant responses.
- Nightly Batch Summarization: Automate nightly processing tasks for summarization.
- Streaming Pipelines: Ingest logs and answer queries in real-time using streaming pipelines.
Conclusion
By combining Databricks with LlamaIndex, organizations can build robust, scalable, and secure LLM-based applications. Integrating these two platforms allows enterprises to seamlessly manage large-scale unstructured data, perform advanced retrieval operations, and generate actionable insights with minimal latency.

FAQ'S
1. Why pair Databricks with LlamaIndex for LLM projects?
Because Databricks handles data scale, security, and real-time serving, while LlamaIndex brings flexible retrieval—together, they simplify turning messy enterprise data into LLM-ready insights.
2. How do I make embeddings searchable within Databricks?
You can store and query them natively using Databricks Vector Search—no need for external tools or complex pipelines.
3. Can I make LLM responses happen in real time?
Connect LlamaIndex to Databricks Model Serving using webhooks to power live, responsive LLM-driven applications like AI copilots and customer chatbots.
4. How do I manage access and security across my LLM pipeline?
Use Unity Catalog to control access, apply masking, and keep your data usage audit-ready—all from within Databricks.
5. What’s the best way to keep my indexes available across clusters?
Persist them in Unity Catalog Volumes or track them with MLflow, so your work doesn’t vanish when clusters stop.